
You can use R in Q to create bespoke tables and do flexible data manipulations. In doing so, you end up with tables within R Outputs. These R tables cannot be manipulated with the feature in the Table Context Menu. These items are designed tables that you build from questions in your blue and brown drop-down menus. Tables you make with R you need to manipulate with R.
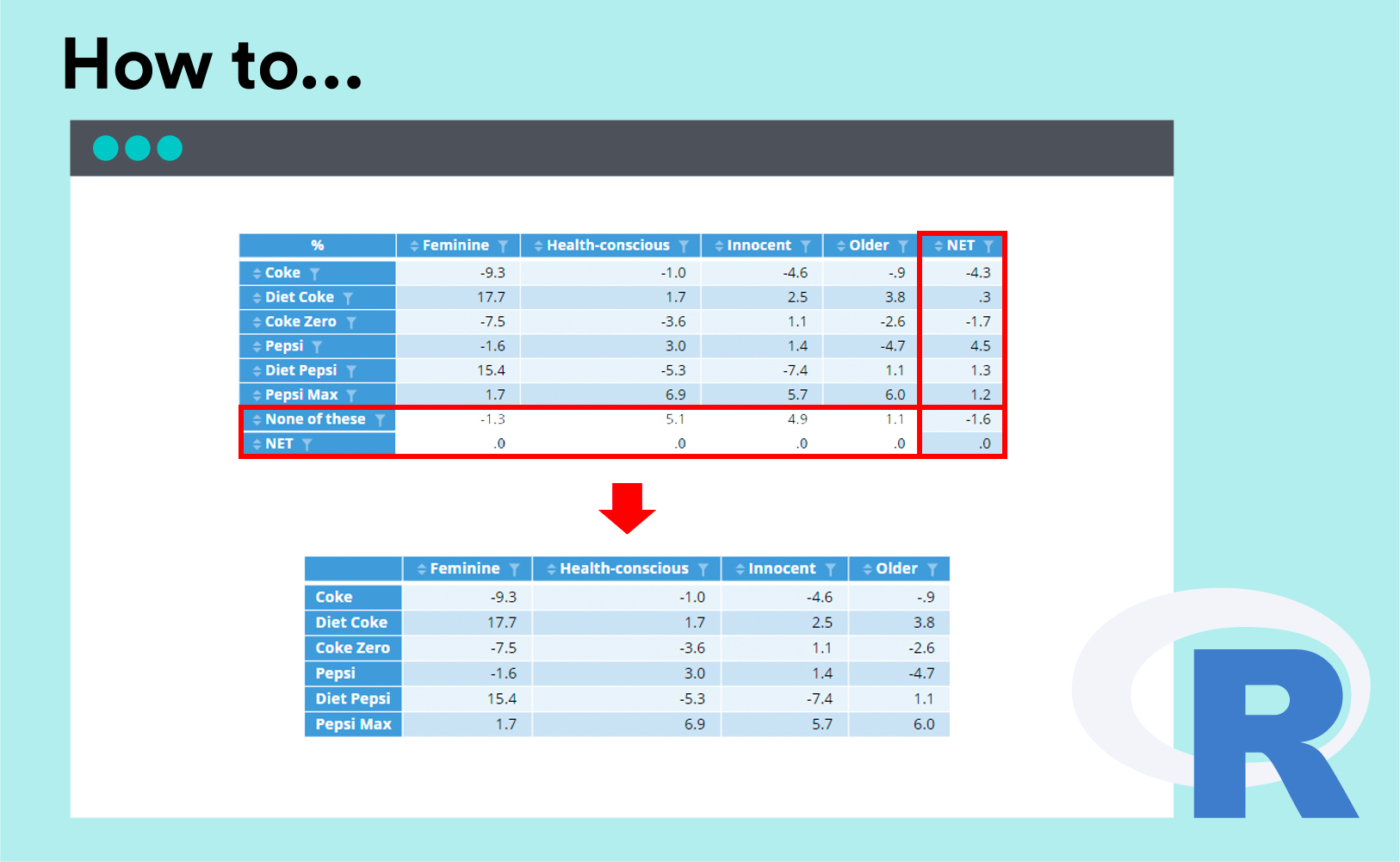
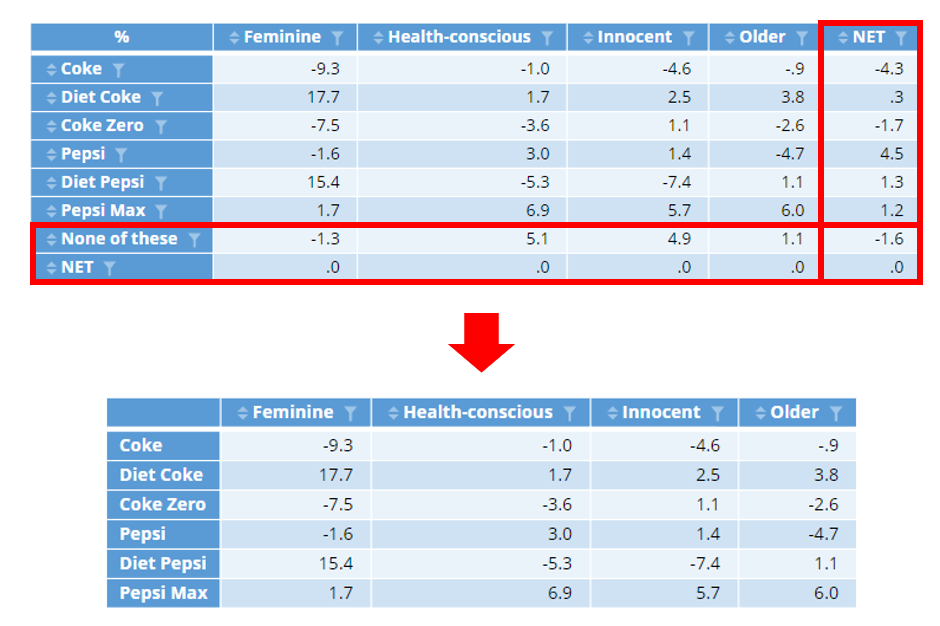
Consider the table below that is within an R Output. (It has been generated by subtracting the scores between two sources tables: the scores for males in one table minus the scores for females on a similar table). What’s important here is that in the output the “None of these” row and the NET row/column have carried over. We may want to remove them in our final R Output:
One way to accomplish this is to go back to the source tables and remove them there (without the need to fiddle with any R). But there are situations where you may not want to change the source question or you can’t change it (for whatever reason). The good news is that removing a row or column from your R outputs is very easy to do with just 1-2 lines of additional code. In this post, I’ll demonstrate how you can use some code to do this, by:
- Specifying the rows/columns to remove by index
- Specifying the rows/columns to remove by name
The second one is likely the most useful of the two because often we want to remove a particular row/column rather than the 1st, 8th or last row/column.
Note: If the terms subsetting and index are unfamiliar to you, I suggest reading this introductory post: How to do Simple Table Manipulations with R Using Q. In all the below, the reference name of the R Output we’re referring to is “table".
Specifying the rows/columns to remove by index
Let’s say you wanted to remove the “None of these” and the “NET” row. A simple way to do it (provided the order of your rows isn’t likely to change) is to just specify the rows you want to keep:
table[1:6,]
But you could also use a minus sign (-) and then specify the rows you don’t want to keep. So in this alternative, we’re saying we “don’t want the 7th and 8th row”.
table[-(7:8),]
This is all very well and good, but it becomes a bit problematic if the ordering of your rows changes. With an update to the data, the NET suddenly becomes the 9th row. Perhaps then you’re better to specify the labels for the rows, as per the next section.
But there is one more trick you can do with specifying by index, and that is to remove the last couple of rows. In this case, the code is as simple as:
n = nrow(table) table[-((n-1):n),]
Here we’re getting the code to first calculate the number of rows, and storing that as n. Then, in the subset on the next line, we’re asking it to NOT return the second last to the last row (ie: remove the last 2 rows). I could have put the above all on one line, but I think it’s easier to see what’s going on with the n this way.
Specifying the rows/columns to remove by name
If you change the source tables (e.g. by updating the data to add, subtract, or sort rows/columns), the ordering of the R Output may be out-of-date, and so we could end up removing the wrong row. I want to be confident the updates to my R Outputs will be accurate and correct. For that reason, I prefer to specify the names of the rows or columns I’d like to remove. To do this, I use the function setdiff() which figures out what to retain (i.e. what remains after you specify what to drop).
x = setdiff(rownames(table),c("None of these","NET"))
y = setdiff(colnames(table),"NET")
table[x,y]
Let me break it down for you:
- On the first line, the
setdiff()function calculates the difference between all the row names in the original table and the array of labels I’ve specified using the combinefunction(). So the remainder is just the six brands. I’ve stored this array of 6 brands asx. - Likewise, I’ve done the same for the columns, storing it as
y. Because there’s only one ("NET") I didn’t need to use the combine functionc()when inputting it into thesetdiff()function. - And then on the third line, I’ve asked the R Output to subset the table by
xandyrespectively.
Try for yourself
The examples above can be found on this QPack here.




