
How to Do Simple Table Manipulations With R in Q


R is not just a tool for the data science elite. It is an immensely powerful tool that can be used by market researchers in everyday analysis. (Q helps make this possible by providing an easy to use interface that is integrated with your project and data). In this post, we’re going to focus on how you can use some simple R to manipulate tables. Specifically, we’ll look how R can be used to compute new rows and columns. We’ll look at how this is done through worked examples. The intention, of course, is for you to be able to take away the principles of the code, so that you can adapt and apply it flexibly and easily in your project.
The computations we’re going to look at in this post include:
- The difference between 2 columns (or rows)
- Creating a custom index score (involving multiple categories in a table(s))
- The average across a series of statistics (eg: the average of a row or column in a table)
- Inserting any of the above back into your original table (ie: inserting a new row or column)
- Calculations involving entire tables (not just rows or columns, but the table in its entirety)
- How to rename columns and rows of an existing R table
A recap on some key concepts
I recommend you read the post on How to build a Brand Funnel in Q using R because I cover off some basics of R.
As a refresh, there are some key concepts for using R in Q:
- Reference names – this is the name that Q uses in R code to refer to another table. In the Report tree, you can right-click on a table and select Reference name. Then you can change the reference name to anything you like (something perhaps easier to remember and type)
- Subscripting – this is how we reference cells within a source table in R. We put either a number or some “text” in [square brackets]. If there are two dimensions to the source table (rows and columns) we use items separated by a comma [rows, columns]. But as we explore in How to build a Brand Funnel in Q using R, with a two-dimensional table, you can reference an entire slab (rectangular slice of the table) by leaving either the row or column item reference blank. That is, a blank before or after the comma.
- Calculate and Automatic calculations – After you write or change any R CODE in the Object Inspector, you need to either click Calculate or check the Automatic box. I recommend not ticking Automatic until you’ve finished with all your coding. That way it’s not going to keep re-updating every time you touch a line of code. You want it to be automatic after you’ve finished, so your R output always stays up to date.
- Blue reference highlighting – if Q is successfully able to identify a reference name of a table or another R output in the report, it will highlight in blue. If it’s not highlighted in blue, it’s not referencing something outside that coding window. If you hover your mouse over anything that highlights in blue like this, it should pop up a representation of the object being referred to (for convenience).
- Functions in R are Case SeNSitIVe – so there’s no particular logic why
rownames()androwMeans()as functions include or don’t include a capital (most capitalize the second word and so on within the function name). You just need to make sure you get it right!
In the image below, I show a right-click on a table of Preferred Cola by Gender. I set the reference name of this table to be pref_tab so when I hover my mouse over it you can see that reference name in the little white box that appears, as shown in the image next to it below.
Calculating the difference between two columns
When you want to calculate the difference between two numbers, you minus one from the other. That seems pretty obvious (4 – 3 = 1). But likewise, you can subtract one variable from another to produce a new variable (eg: x – y = z). The variable z will therefore change as x and y change. In R, the same principle can apply to rows and columns of tables (and actually to entire tables, as we’ll discuss at the end). We can let the row or column act as variable. In R terms, this is called a vector.
Let’s show this via example on the table below (Preferred Cola by Gender, which has a reference name of pref_tab).
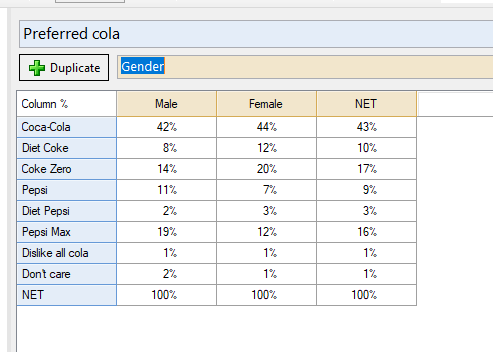
We could consider the entire column Female to be y. So the first line code would be: y = pref_tab[,"Female"]
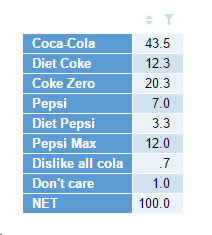
Then the Male column, on the second line of code, we could store as: x = pref_tab[,"Male"]. Therefore, the difference between y and x is simply y – x (that’s my third line). I could just leave it at that, but I’m going to do a bit of further housekeeping on the output. I’m going to store it as a vector called z (so I can use z later in other computations, if I choose). So I’m going to change my third line to be z = y – x. Second, in the toolbar in the Outputs tab in Q, I’m going to remove the decimal places and apply a percentage sign. The final result is then the below:
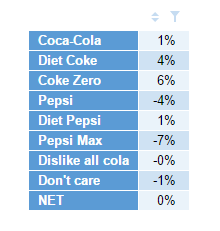
And there you have it – the difference between Female and Male for all the brands. I didn’t have to calculate the brands separately, it did it all just at once, because I was referencing columns that were side-by-side in a table (and so I know all the order of the brands align in the vectors x and y). The resultant z variable keeps names of each item in the vector.
Creating a custom Index score across multiple categories
Researchers like to use different metrics in the course of their work. Sometimes these metrics are indexes that they have to replicate, or they make up themselves. These go beyond the simple adding or subtracting of percentages (as in the above), as in the creation of custom index scores. The computations behind these scores can be whatever you like. The beauty of a tool like R is that it allows you to pick up numbers from your table, play with them (ie: do computations with them), and then put them back together. And once you’ve set it up, it should just update automatically when new table comes in, or if you modify something in the source tables.
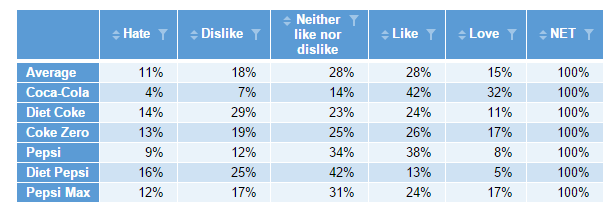
Again, I’ll show how you can do this via example. Bear in mind that the below index calculation is something I’ve made up. The purpose of the worked example is to demonstrate the logic behind the R code so that you can adapt it to whatever scenario you’re in. In the example, we’ll use the following table, which is a summary table of a attitudinal scale question (a Pick One – Multi in Q terms). Respondents in a survey were asked to rate their attitude towards 6 different cola brands on a scale from Hate to Love. I gave it a reference name of brand_att for convenience.

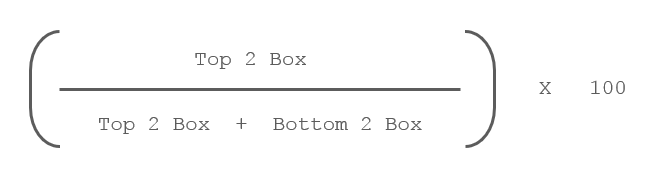
Let’s say I need to create a special index, based on the following formula. It is basically the top 2 box score, divided by the sum of the non-neutral scores, for each brand. So for Coca-Cola this index would be (42 + 32) / ((42 + 32) + (7 + 4)) * 100 = 87.
My first line of code would be to calculate the top 2 box: t2b = brand_att[,"Like"] + brand_att[,"Love"]. Notice that I’m storing my top 2 box array as a variable called t2b. The variable isn’t a single number, but rather 6 consecutive numbers, each tagged with the brand name in the same order as the source table (Coca-Cola thru Pepsi Max). The next line would be the bottom 2 box: b2b = brand_att[,"Hate"] + brand_att[,"Dislike"].
And then I can work my index out using basic algebra on my variables. I could have squashed lines 3 through 5 in the below into the one line, but I’ve split it out just for the sake of illustration and made new variables numerator and denominator.
t2b = brand_att[,"Like"] + brand_att[,"Love"] b2b = brand_att[,"Hate"] + brand_att[,"Dislike"] numerator = t2b demoninator = t2b + b2b index = (numerator / demoninator) * 100
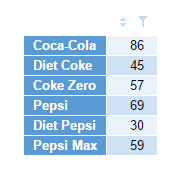
The average across a series of statistics
Sometimes we want to compute the average of statistics in a table. This is different to computing the average of variables. The latter is computed at the respondent-level (each respondent gets a value). You can use R variables to do that, or make a JavaScript variable. By contrast, we are generating the average of statistics in an R Output, working with the outputs from other tables.
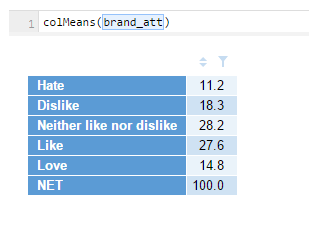
To do this, R actually has a function for this purpose ready to go. It saves us having to specify the arithmetic as I did in my worked example (11.3%) a moment ago. To use a function in R, you write the function name and then enclose in rounded brackets the bits you want the function to act on (called the arguments in R terminology). In this case, we have two useful functions: colMeans() and rowMeans(). I put the () brackets after them to reinforce the point they are functions (and need stuff to go inside their brackets). To see how this could apply to the Brand Attitude table above, you could do the following (note: rowMeans() wouldn’t make much sense in this example!).
Let’s consider how it can apply to another table. Consider this Pick Any – Grid question called Brand Image. Respondents could freely click as many of the cells below in the survey.
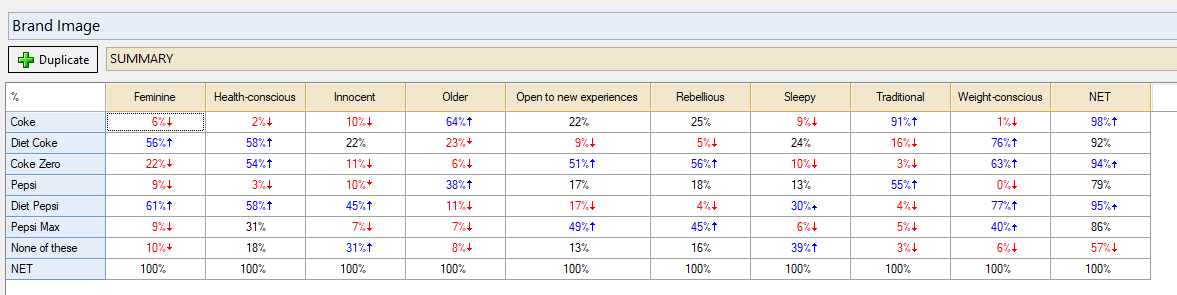
I can use colMeans()to create an average across all the brands for each attribute: attribute_average = colMeans(brand_image).

Simple right?
Wrong. Well, it’s sort of right. It’s right in the sense that 34 is the literal average of all the numbers in the Feminine column. But this is including the None of these and even the NET categories, which you are likely to not want to include in the computation. So how do you exclude those two categories? You could change your source table (ie: in Q, select the None of these and the NET categories, and then right-click > Hide). That would change how the question is represented everywhere in the Q project, so you may like to duplicate the question first and alter the duplicate.
The other way would be to subscript your source table in the R code, so that we’re only extracting the rows and columns we want. To do that, I could specify which brands I want (and in which order) by using an array. We make the array by using the combine function c(). (See How to Build a Brand Funnel in Q using R for an in-depth discussion of referencing rows and columns arrays of brand labels). I would use the brand array to the colMeans() and the attributes. When it comes to the rowMeans(), I don’t want to include the NET column (which is 100 for each row). So I would similarly do the same by making an attributes array to use when referencing the table. Although specifying the labels seems a little tedious, it’s a case of a stitch in time: you are not at risk of accidentally referencing the wrong rows.
brands = c("Coca-Cola","Diet Coke","Coke Zero","Pepsi","Diet Pepsi","Pepsi Max")
attribute_average = colMeans(brand_image[brands,])
attributes = c("Feminine","Health-conscious","Innocent","Older","Open to new experiences","Rebellious","Sleepy","Traditional","Weight-conscious")
brand_average = rowMeans(brand_image[,attributes])
Inserting your computation back into your original table
In all the outcomes above, we can see a new array of information (mostly by brands, but sometimes by attributes as in the last example). We’ve got the numbers, but you may like to integrate this back into your original table. Perhaps just to give it some context, or perhaps you want to feed the overall table into a visualization or report or whatever.
It’s quite easy to do, and just involves adding a couple more lines of code to everything you’ve done this far. R has functions called rbind() and cbind(), which are row-bind and column-bind respectively. But at Q/Displayr we have better functions (we believe) called Rbind() and Cbind() respectively (with capital first letters). These are part of our flipTables package. To use these functions in Q, add the line library(flipTables) upfront, as I do below. The reason why these functions are better than the Standard R is that they can match row and column labels. This may alleviate the need to create brand arrays when combining tables, or at least act as an additional safeguard to ensure things align properly.
We’re going to use these functions to “bind” the row and column mean arrays to the original table. Let’s take our first example, the difference between the genders on their main cola. There’s a couple of ways we can include the new array that represents the differences in the original table. One way is to tell R to combine the original table with the new array column-wise with the 5th row of code below.
library(flipTables) y = pref_tab[,"Female"] x = pref_tab[,"Male"] z = y - x table = Cbind(pref_tab,"Difference" = z) table[,c(1,2,4)]
In the above, I’m specifying the label for the column. I just put the desired label in speech marks “” and let it equal the variable: "Difference" = z
The NET is a bit annoying, and I may not want to see it. One way to remove it is to remove it or hide it from the source table pref_tab. Another way, is just to tell the R code that we only want the 1st, 2nd and 4th columns: table[,c(1,2,4)]
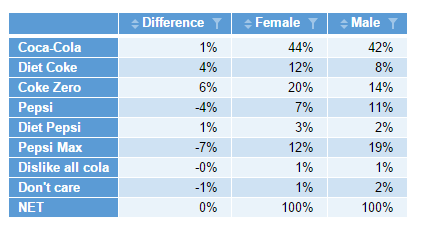
There’s also another way to achieve the above as well. Given I’ve got x, y and z set up as variables, I could column-bind all three, and give them labels at the same time. I’ve purposively changed the order of the columns to prove the point! A new arrangement in the table is flexible and at your control!
y = pref_tab[,"Female"]
x = pref_tab[,"Male"]
z = y - x
table = cbind("Difference" = z,"Female" = y,"Male" = x)
On our brand attitude table in the post above, we could use rbind() to place the average % across brands as a row at the top (plus give it a label). It’s just:
a = colMeans(brand_att)
table = rbind("Average" = a,brand_att)
Finally, if you wanted to add the row and column averages to the Brand Image table, you can apply both rbind() and cbind() to the one table. Noting, of course, that you need to use rbind() and cbind() the right-way around!
attribute_average = colMeans(brand_image[1:6,]) brand_average = rowMeans(brand_image[,1:9]) table = rbind(brand_image[1:6,],"Average" = attribute_average,"None of these" = brand_image["None of these",]) cbind(table[,1:9],"Average" = brand_average)

A word of caution: Using rbind() and cbind() won’t match your category names (eg: brands). So if the thing you are row-binding or column-binding has a different order of brands, or mismatching category labels, you may be better exploring other functions, such as the MergeTables() or Merge2Tables() (available via the Create > Tables menu in Q). In this case, my 4th line of code above is leading to an error, which I’ve highlighted in yellow in the image above. The 15.8 is actually the average for “None of these”, so it doesn’t match up! In this particular example, I would have been better to just recompute the rowMeans() again, so I’ve done that in the version below. Much better!
attribute_average = colMeans(brand_image[1:6,]) brand_average = rowMeans(brand_image[,1:9]) table = rbind(brand_image[1:6,],"Average" = attribute_average,"None of these" = brand_image["None of these",]) cbind(table[,1:9],"Average" = rowMeans(table))
Calculation involving entire tables
I just want to briefly mention that R is smart enough to do calculations that match up entire tables, not just rows and columns. You can do computations on entire slabs (rectangles) of information. In R lingo, a rectangular slab of information is treated as a matrix.
Here’s a simple example. Suppose I had my original Brand Image table above, but I had two versions of it. One table filtered by males. The second other filtered by females. I give each of these reference names of brand_image_male and brand_image_female respectively. Then, I can simply subtract one from the other to get the difference. Yes, it’s that easy.
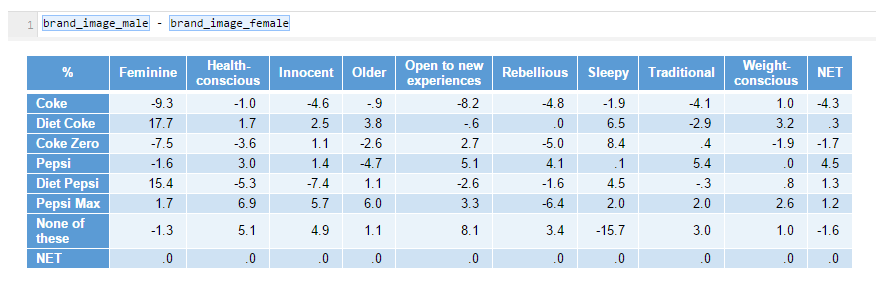
This could make for a delicious visualization, so why not try hooking this last output up to a visualization? I’ve done that in the example QPack.
How to rename columns and rows of an existing R table
Tables made with R are different to those that you can make with Q normally. See the section “Creating an R Output” in this post for more detail on how R tables are different. Inconveniently, you can’t just right-click on a category in an R table to rename it. You need to use a bit of code in order to rename the columns or rows. In the post above, we mentioned how you can set the row or column labels at the time you are using rbind() or cbind(). But you can also change the row and column labels on a completed table using the functions rownames() and colnames(). Here’s how to do it.
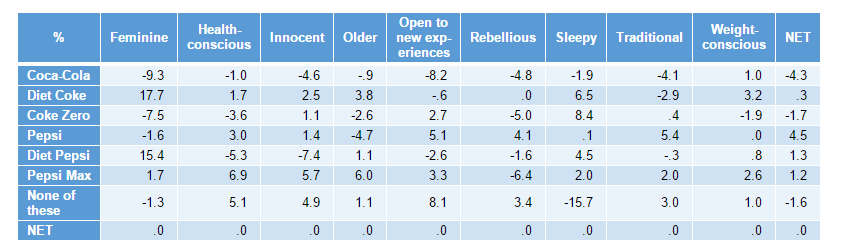
Take the Brand Image table from above where I calculated the difference between the male and female scores in the grid. Say I wanted to change the label Coke to Coca-Cola. I could do that using rownames() and specifying the new row names using the combine function c(). Note: on the third line of code, I had to repeat table to return the table as the output, otherwise it would just return the string of brand names I’ve specified on the second line.
table = brand_image_male - brand_image_female
rownames(table) = c("Coca-Cola","Diet Coke","Coke Zero","Pepsi","Diet Pepsi","Pepsi Max","None of these","NET")
table
But that was a bit of a bore having to write out all the row names again. Imagine if there were lots and lots of rows! And, I could easily have made a mistake. I could have swapped Diet Pepsi and Pepsi Max around, and hence made a mislabelling error. To get around this, I could alter the code so that I’m just renaming the Coke bit, and nothing else:
table = brand_image_male - brand_image_female rownames(table)[rownames(table) == "Coke"] = "Coca-Cola" table
Conclusion:
Here I have discussed just some applications of R. Really, you are only limited by your imagination as to what you can do with your data. We invite your feedback and questions about the content. Do let us know if there are other ways we can help you use Q better.
I invite you to see the code in action, and play with it, in Q. You can download the QPack from here. If you don’t have Q, you can request a trial from the Q website.




