How to Identify Duplicates in Q Using Code
In market research, you may end up with a data file that contains duplicate records. This can happen when your survey creates a new record each time the link is accessed, such as an open survey link embedded on a website, which allows the same participant to complete the survey multiple times. While a blog post has already been published regarding tips for handling duplicate cases, this post will show you how to identify and remove duplicates in your survey data using code.
I will now outline how you can detect duplicate records in your data set with both JavaScript and R. In this example, I have a data set on cola which includes duplicate records that I want to delete. I know there are duplicates because there are non-unique values in my numeric id variable, ‘UID’.
Which duplicates should be kept and which should be removed? The two most common cases are to either keep the person’s first response or their last. In this post, I will show how to retain both the first and last instance of each of the duplicated records. The techniques assume your respondents are sorted in chronological order of their survey date.
Identifying duplicates via JavaScript
You can create a binary filter of all the duplicate records using a JavaScript variable by following the below steps:
- Go to the Variables and Questions tab
- Right-click any row and select Insert Variables(s) > JavaScript Formula > Numeric
- If you wish to keep the first instance of a duplicate, paste the code below into the Expression field:
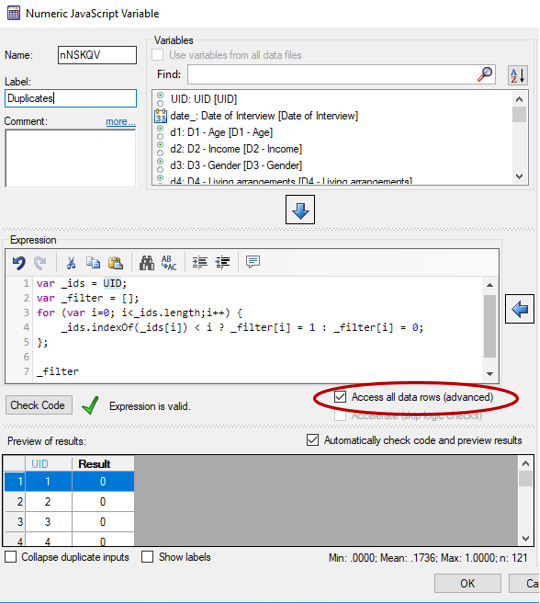
var _ids = UID; var _filter = []; for (var i=0; i < _ids.length;i++) { _ids.indexOf(_ids[i]) < i ? _filter[i] = 1 : _filter[i] = 0; }; _filter
If you wish to keep the last instance of a duplicate, paste the code below into the Expression field:
var _ids = UID; var _filter = []; for (var i=_ids.length-1; i >= 0;i--) { _ids.lastIndexOf(_ids[i]) > i ? _filter[i] = 1 : _filter[i] = 0; }; _filter
In this JavaScript code, we loop through all the record numbers to create an array called ‘_filter’, which returns a 1 if the id number already exists in a previous iteration and 0 if it does not.
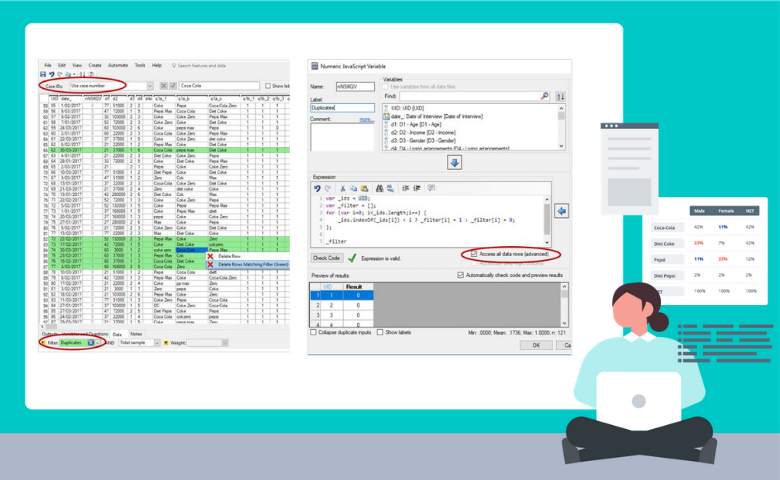
- Tick Access all data rows (advanced) on the right below the Expression box.
- Change the Label to ‘Duplicates’ and click OK.
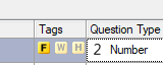
- Press the F in the Tags column for this variable to turn it into a Q filter.
Identifying duplicates using R
While using JavaScript code in Q is generally more efficient than R, you can create a binary R filter with a single line of code by following the below steps:
- Go to the Variables and Questions tab
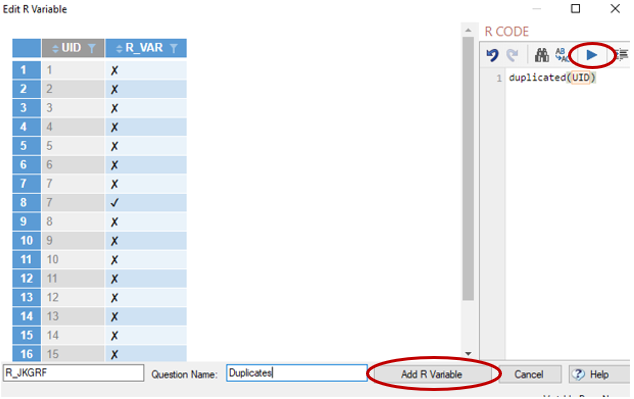
- Right-click any row and select Insert Variables(s) > R Variable
- If you wish to keep the first instance of a duplicate, paste the code below into the R CODE window:
duplicated(UID)
If you wish to keep the last instance of a duplicate, paste the code below into the R CODE window:
duplicated(UID, fromLast=TRUE)
With R we simply need to reference the id variable and use the duplicated function so that it returns a 1 for the duplicates and 0 for the non-duplicates.
- Press the blue Play button
- Name the variable as ‘Duplicates’ and press Add R Variable
- Press the F in the Tags column for this variable to turn it into a Q filter
Deleting duplicate cases
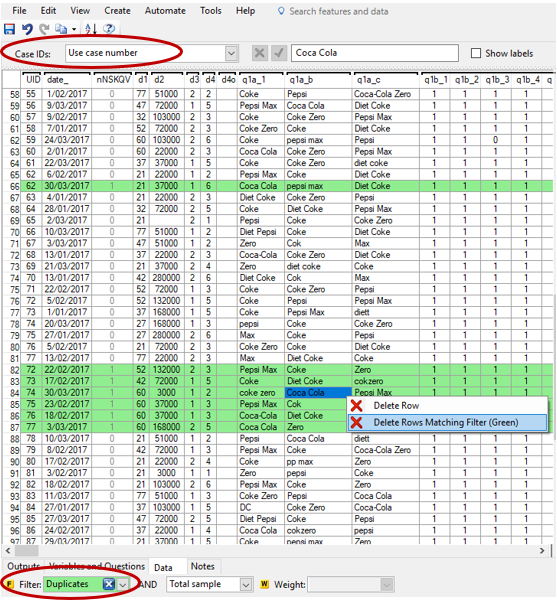
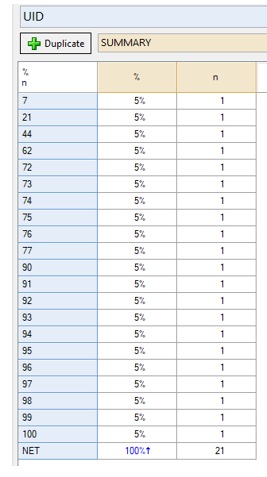
If we apply this filter on a table, we can see there are 21 duplicate records which we need to remove.
Once these cases have been identified, the next steps are performed in the Data tab:
- Select any unique identifying variable from your data set in the Case IDs drop-down at the top left above the data pane. If you don’t have one, you can use the Use case number option instead. However, this is not recommended for projects where the data file will be updated, as it simply uses the position of each record which could then change.
- Next, you need to apply the duplicates filter to the Filter drop-down on the bottom left. The rows which correspond to the filter selection will be highlighted once selected.
- If you then right-click on any row and select the Delete Rows Matching Filter (Green) option, Q will remove all the duplicates from your Q project.