
Tips for Handling Duplicate Cases in Survey Data
There are some situations when your survey data file may contain duplicate values in your record identifier field. This can occur, for example, when some respondents have data in more than one row of data in the file. In this case, there may still be a need to have a unique identifier for each of these cases. There may also be times when you have duplicate records that need to be removed from the file. In this post, we will deal with both of these scenarios.
For the first scenario, we’ll show you how to create a new unique identifier variable from the original ID. The method used here is to append an incremented value to the original identifier for each subsequent duplicate case. For example, if the case ID 10421 appears twice in the data file, the new unique identifier variable will have values of 10421 and 10421_1. Once the new ID variable has been created, a new SPSS data file is generated which is then used in place of your existing data file.
In the second scenario, we’ll explain how to identify and remove duplicate records from the data file.
Importing your data
For both scenarios you will want to save a new copy of the raw data file so that the changes will be hard-coded. You need to first open our current data file in a new Q project but without any of the automatic setup functions:
- Select File > New Project.
- Select File > Data Sets > Add to Project > From File.
- In the Data Import Window, select Use original data file structure.
- Expand the Advanced section and uncheck Tidy Up Variable Labels
- Uncheck Strip HTML from Labels.
- Click OK.
The data file will be imported using the original file structure and labeling. This prevents Q from making any additional changes to the data file. For more information on best-practices to use when saving a new copy of the data file, see How to save a modified copy of an SPSS data file.
Creating a de-duplicated ID variable
Once the file has been imported, the next step is to use a bit of JavaScript to create the new unique ID variable.
- Go to the Variables and Questions tab.
- Right-click the ID variable and select Insert Variables > JavaScript Formula > Text.
- Tick the box Access all data rows (advanced).
- Paste the code below into the Expression section of the Text JavaScript Variable dialogue box.
- Change UniqueID in the first line of the code to the Variable Name of your original unique ID variable.
- Enter an appropriate Name and Label (NewID or something similar) for the new variable.
- Click OK to save the variable.
The code to use is:
var _old_ids = CustomerID;
var _new_ids = _old_ids.map(function (x) { return x.toString(); });
_new_ids.forEach(function (_i, _ind) {
if (_new_ids.indexOf(_i) < _ind) {
var _counter = 1;
while(_new_ids.indexOf(_i + "_" + _counter.toString()) < _ind && _new_ids.indexOf(_i + "_" + _counter.toString()) > -1)
_counter ++;
_new_ids[_ind] = _i + "_" + _counter;
}
});
_new_ids
A new unique identifier variable file will be added to the data. You can examine the new variable in the Data tab.
Deleting duplicate cases
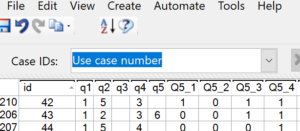
We next need to set a unique identifier for the data. Go to the Data tab and from the Case IDs dropdown box, select Use case number. This option will use the position of the respondent in the file, in other words the row number, as the unique identifier. Click OK on the warning message that appears.
Identifying duplicates
This is done by changing the original identifier variable to categorical and then creating a table from this variable. To illustrate, we will use the sample file Phone.sav which is included in your Q Examples folder. The identifier field “IID – Interviewer Identification” contains duplicate values. Since the “IID – Interviewer Identification” variable is numeric, we must first change this to a categorical variable. We can then create a table which will identify records with duplicate id’s.
- Go to the Variables and Questions tab.
- Change the Question Type for the variable IID – Interviewer Identification to Pick One.
- Go to the Outputs tab and create a table using by selecting IID – Interviewer Identification in the blue drop-down box.
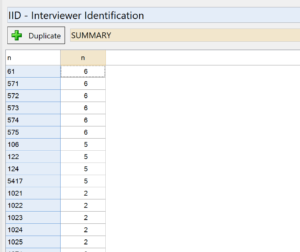
- For this particular exercise, we want the n statistic displayed in the table (instead of column %) since we are interested in the count of each id. To do this, right-click on the table, select Statistics – Cells and, while holding down your Ctrl key, first select n and then deselect %.
- Right-click on the column header and select Sort by > Values – Descending > n. This will sort the table in descending order. Note that any row with n > 1 represents a duplicate id.
Creating a filter
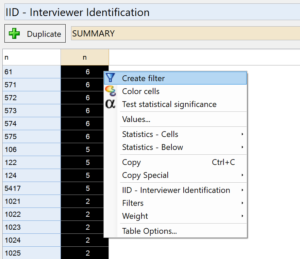
The next step is to create a filter based on the table. To create the filter, first highlight all cells with a value greater than 1, then right-click and select Create filter.
Enter a name for the filter and click OK.
Deleting duplicate records
We are now ready to delete the duplicate values.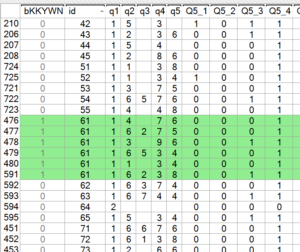
- Go to the Data tab.
- Sort the data by right-clicking on the id variable which will be the second column using our example file (the filter variable is the first column) and select Sort Data by this Column – Ascending.
- From the Filter drop-down box at the bottom, select the filter created above. Note that records with duplicate id’s will now be highlighted in green.
- To delete individual rows, right-click on the row and select Delete Row.
To learn more about working in the data tab, including filtering and deleting records, see Tips for working in the Data tab.
Creating a new SPSS data file
For both scenarios, you likely want to save out the modified version of the data file. Be sure that you have used the steps above when importing the data set.
To save a new copy of your file with the duplicated cases removed, or with the new de-duplicated ID variable included:
- Select Tools > Save as SPSS/CSV File.
- Click OK on the notification screen (to learn more about this notification screen, see How to save a modified copy of an SPSS data file).
- Enter a file name, select a location on your hard drive to save new file to and click Save.




