
Using Correspondence Analysis to Compare Sub-Groups and Understand Trends
This post shows how to use correspondence analysis to compare sub-groups. It focuses on one of the most interesting types of sub-groups: data at different points in time. This is variously known as trend, tracking, longitudinal and time series data. The end-goal is a visualization showing key comparisons, such as the visualization above. Here we see how the positioning of different tech brands has changed over time. Thus, we are trying to do to two things at once:
- Create a correspondence analysis plot that shows key relationships (e.g., between brands and attributes, as above).
- Show how differences in these relationships vary by sub-group or over time.
The data – technology brands in 2012 and 2017
The data looks at tech brands, comparing how people think about the brands in 2017 versus how they were perceived in 2012. Looking at the two tables below, you can probably get a good feeling for the difficulty of the problem: there is just too much data in these two tables for somebody to scan them and see the key patterns.
Step 1: Stack the tables
The first step is to create a new table, like the one below. This consists of the two tables from above glued together (i.e., stacked), with labels clarifying the meaning of each row. In this example we just have two sets of data (2012 and 2017), but there is no limit to the number that can be used.
In gluing together the data by stacking one table on top of another, we are making an assumption, which is that the relationship between the attributes can be regarded as being fixed over time. This is very much an assumption of pragmatism: it is unlikely to be true, but the alternative is mind-bendingly complex. If we do not fix the attributes, it becomes hard to work out if brands have moved, or, if the brands have stayed constant and the attributes (e.g. our perception of Stylish) have moved.
Step 2: Standard correspondence analysis
Once we have our table, we can just apply normal correspondence analysis, as I have done below. The further apart two time periods for a brand, the greater the difference between the sub-groups should be.
As always, it pays to confirm any key conclusions by checking the actual data. This is particularly important when comparing sub-groups, as sometimes the explanations are a bit more nuanced than is obvious.
Looking at the brands on left, we can see that both Google and Yahoo have moved towards the right (i.e., to quality, high performance, and style) in the past five years. However, the reasons are completely different. Google has improved. Yahoo has gone backwards in everything, but as its performance and style were already close to rock-bottom, they could not move much further and thus, in relative terms, Yahoo improved!
Step 3: Use arrows
I, personally, find the map above to be a bit too busy. The simple fix is to use arrows instead of the points, as done below. This only works well if you have trend data, or, only two categories. We can now see the big story: Apple’s advantage in Style has diminished over the past 5 years.
(Optional) Step 4: Statistical tests
In theory, it is possible to conduct statistical tests on correspondence analysis, although it is pretty unusual to do this outside of South Africa (where correspondence analysis seems to have the ubiquity that regression has in the rest of the world). I usually find it is better to instead conduct statistical testing on the raw data, and pool any data that is not statistically significant. The reason I prefer this approach is that the whole point of correspondence analysis is to compare relativities, so if one brand has moved, then all the relativities must change. Thus fixing a brand makes little sense to me.
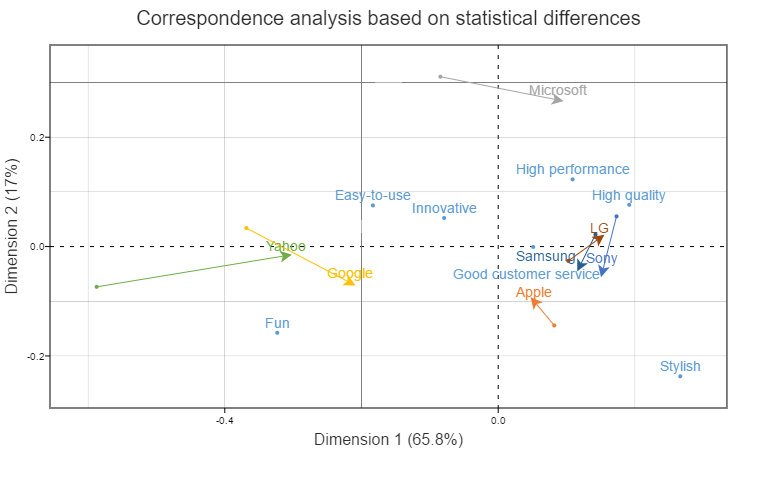
In the tables above, Apple’s Fun score moved from 46% to 64% from 2012 to 2017. This is highly significant. By contrast, Microsoft’s Fun score moved from 17% to 22%, which is not statistically significant (at the 0.05 level). So, when creating the stacked table again, I left Apple’s Fun scores at 46% and 64%, but changed Microsoft’s to 19.5% for both 2012 and 2017. I did this for all the 56 cells in the table (performing the tests using z-tests of proportions, and then applying the false discovery rate correction at the 0.05 level). Then, I conducted the correspondence analysis again. The results are essentially the same, perhaps meaning I have wasted my time. I nevertheless choose to believe that it means I have verified that my first analysis was relatively robust.
One note of caution when you do pooling of non-statistically significant differences, as I have done here. You may have a brand that is found not to have any differences. Yet, it will still move on the resulting plot. This is because correspondence analysis is focusing on the relativities, so even if a brand’s data has not changed, any movement by competitors will cause the relative position of all brands to move.
If you want to follow through the steps that I used in performing the statistical testing in more detail, click here (which will take you to a Displayr document that contains the calculations).
Software
All the examples in this post have been created using the CorrespondenceAnalysis function in the Displayr/flipDimensionReduction package on github, which automates all of the steps above. Click here to open up the Displayr document that contains all of the data, outputs, and R code.
Within Displayr, correspondence analysis with trends or sub-groups are conducted by:
- Creating tables for each sub-group or time period.
- Insert > More (Analysis) > Dimension Reduction > Correspondence Analysis.
- Select the Multiple tables option.
- Select all the tables.
- (Optionally) Choose Trend lines.
- Press Compute or check Automatic.
In Q, the analysis is conducted using Create > Dimension Reduction > Correspondence Analysis and then following steps 3 through 6.


