
Testing Whether an Attribute Should be Numeric or Categorical in Conjoint Analysis
Choice-based conjoint (CBC) studies usually specify a fixed number of levels for each attribute. The resulting attribute then becomes categorical. But that doesn’t mean you have to treat these attributes as categorical when performing analysis. There are times when it is preferable to instead treat attributes with categorical values as numeric variables. With Q, you can easily test which method works best with your data.
Most choice-based conjoint (CBC) studies in marketing specify a fixed number of levels for each attribute. For example, a study of the fast food market could test a variety of prices — $10, $12, $15, $20, and $30 — and estimate the utility (or appeal) of each price point. However, in Economics it is more common to treat price as a numeric variable when estimating the choice model, assuming that price has a linear relationship with utility (i.e., a dollar increase in price leads to a constant decrease in utility).
This post describes how to test whether to treat price as a categorical or numeric variable.
The old-school approach
Before explaining how to determine whether an attribute is better addressed as being numeric or categorical, I am going to revisit the approach described in introductory textbooks. For reasons I will later discuss, this approach is not appropriate for conjoint analysis, but it is useful to understand the old-school approach in order to recognize when people apply it inappropriately.
For the vast majority of statistical models — linear regression, logistic regression, and multinomial logit, etc — a statistical test is used to assess whether an attribute (variable) should be treated as being numeric or categorical. The basic process is as follows:
- Compute the first model using the numeric variable.
- Compute the second model using the categorical variable.
- Use an F-Test or Likelihood Ratio Test to check if the improved fit of the categorical model is due to sampling error.
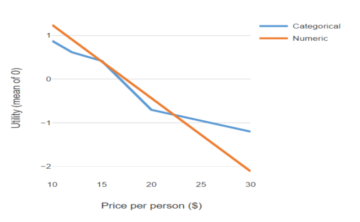
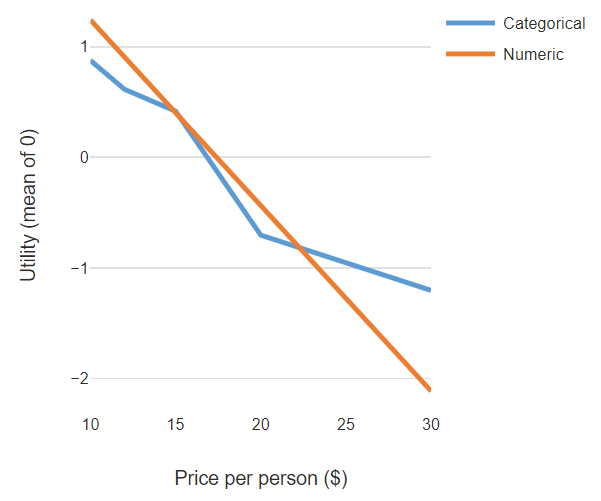
For a more graphical explanation, consider the chart below. The basic idea is to run a significance test to check whether the deviations from the straight line are likely just noise, or if it’s reflective of some key insights into consumer behavior. The old-school approaches begin with the assumption that treating the data as categorical ensures that the model will provide a better fit for the data. They then compute statistical significance by quantifying how much deviation can be expected from a straight line by chance alone.
If the deviation that is observed is less than some plausible level of random deviation, then we conclude that the categorical attribute is not required and we should treat the variable as being numeric (aka linear).
The problem with the old-school approach
The old-school approach is tried and true and works in many contexts. But it does not work for the modern choice models used to analyze conjoint experiments.
The reason for this is that with a modern choice model, it is not even guaranteed that the categorical variable will have a better fit to the data than the numeric attribute. In the example plotted above, for example, the model with the linear (numeric) price attribute has a better fit to the data than the model with the categorical attribute (where fit is quantified as the log-likelihood).
If you have studied some statistics, you will probably be thinking, “How can that be? The categorical model is more flexible so it must fit the data better.” However, that is not necessarily true in the case of modern choice modeling methods, such as hierarchical Bayes (HB). It is the case that the categorical variable is more flexible. However, the plot above only shows the average effect.
Modern choice models also compute estimates of variation between people, and the pattern of variation implied by a numeric attribute cannot be approximated by a categorical attribute. With a numeric attribute, a modern choice model assumes that the relationship between price and utility for each person is its own straight line, with people differing in regard to the slope of the lines. By contrast, when price is treated as being categorical, the conclusion will be that each person’s line is not straight, even if the model estimates a perfectly straight line for the average effect.
The underlying mathematics (for the hardcore only)
The modern choice modeling methods, like HB, include a stage where draws are made from a multivariate normal distribution. Even if the vector of means of this distribution is descending linearly, there is no chance of a random draw from this distribution having values in a straight line. That can only occur when the variance of each variable in the distribution is 0, and that never occurs in real-world studies.
The solution
Fortunately, there is a straightforward way to perform a viable test:
- Randomly divide the sample into two sets of observations:
- The first set which is used to estimate the models
- The second set which is held back and predicted by the model. This second sample is variously known as a holdout or validation sample.
- Compute the log-likelihood of the two different models on the holdout sample. The model with the higher log-likelihood is the better model, all else being equal.
The solution with Q
If you are using Q, this is a straightforward procedure.
Q allows you to automatically hold back and predict the data from a subset of the choices, by clicking on a model and selecting Inputs > MODEL > Questions left out for cross-validation.
The log-likelihoods are shown in the footer of the models. The results for the Categorical model are shown immediately below. The log-likelihood in the holdout data is shown first, and the value for the model fitted to the data is shown in brackets. Below that are the corresponding results for the Numeric model.
In both cases, the log-likelihood is higher (closer to 0) for the model with the numeric attribute. The more important comparison is the value not in parentheses, and that difference is much larger. This further emphasizes the point that the numeric variable is better suited to this data set.
 .
.





