
Old-School Crosstabs: Obsolete Since 1990, but Still a Great Way to Waste Time and Reduce Quality
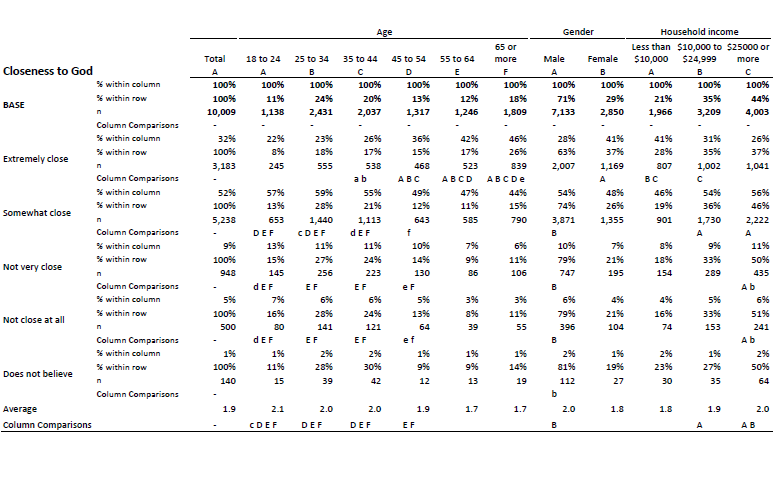
The table above is what I call an old-school crosstab. If you squint, and have seen one of these before, then you can probably read it. The basic design of these has been around since the 1960s.

Originally, these old-school crosstabs were printed on funny green and white paper with a landscape orientation, shown to the right. The printers were surprisingly slow. The ink and paper expensive. The data processing experts responsible for creating them tended to be very busy. So, these crosstabs were designed with the goal of fitting as much information on each sheet as possible, with multiple questions shown across the top.
Advances in computing have led to a change in work practices. Some researchers still create these tables, but have them in Excel rather than print them. Other researchers have taken advantage of advances in computing and stopped using old-school crosstabs altogether. This post is for researchers who are still using old-school crosstabs. It reviews how three key innovations made these old-school crosstabs obsolete:
- Improvements in printing and monitors, which permit you to show statistical tests via formatting.
- Automatic screening of tables based on statistical tests.
- DIY crosstab software.
At the end of the post I discuss the automation of such analyses using Q, SPSS, and R.
Improvements in printers and monitors
When the old-school crosstabs were invented, printers and computer screens were very limited in their capabilities. Formatting was in black and white – not even grey was possible. The only characters that could be printed in less than a few minutes were those you could find on a typewriter. With such constraints, using letters to highlight significant differences between cells, as done in old-school crosstabs, made a lot of sense.
However, these constraints no longer exist. Sure, an experienced researcher becomes faster at reading tables like the one above, but the process never becomes instinctive. You do not have to take my word on this. Can you remember the key result shown on the table above? My guess is you cannot. Nothing in the table attracts your eye. Rather, the table is something that requires concentration and expertise to digest. For example, to learn that the 18 to 24 year olds are much less likely than older people to feel they are “Extremely close to God”, you need to know that, rather than look in the column for 18 to 24s, you instead need to scan along the row and look for other columns where either a or A appears.
Now, contrast this to the table below. Even if you have never seen a table quite like this before, you can quickly deduce that the 18 to 24 year olds are less likely to be “Extremely close to God” than the other age groups. And, you will also quickly work out that we are more likely to feel close to God the older we get, and that the tipping point is around 45. You will also quickly work out that females and poorer people are more likely to think themselves close to God.
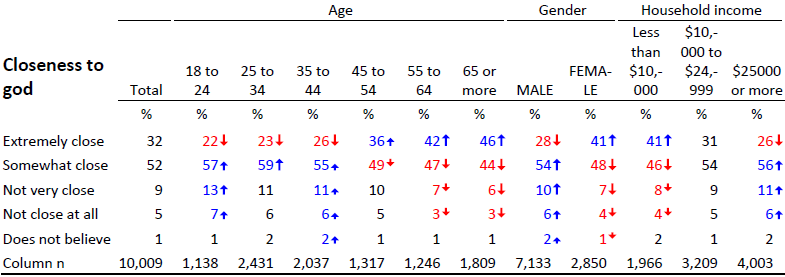
The difference between the two tables above is not merely about formatting. The first table is bigger because it includes a whole lot of needless information (I return to this below). The second table is easier to read because it contains less data. It also uses a different style of statistical testing – standardized residuals – which lends itself better to representation via formatting than the traditional statistical tests (the length of the arrows indicates degree of statistical significance).
We can improve this further still by using a chart instead of a table. The chart below is identical in structure to the table above, except that it uses bars, with these bars shaded according to significance. The key patterns from the previous tables are still easy to see, but they are now easier to spot as they are represented by additional information (i.e., the numbers, the arrow lengths, the bar lengths, and the coloring). We can also now readily see a pattern that was less obvious before: with the exception of people aged 65 or more, all the other demographic groups are more likely to be “Somewhat close” than “Extremely close” to God.
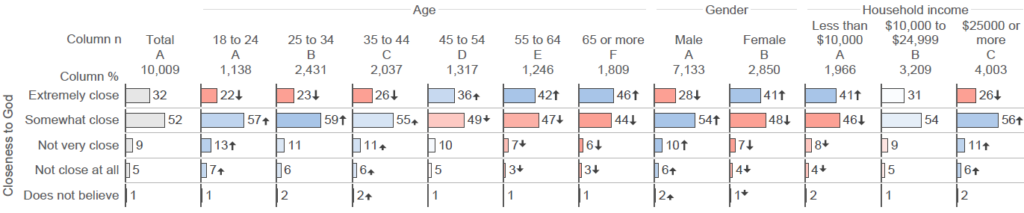
Using statistical tests to automatically screen tables
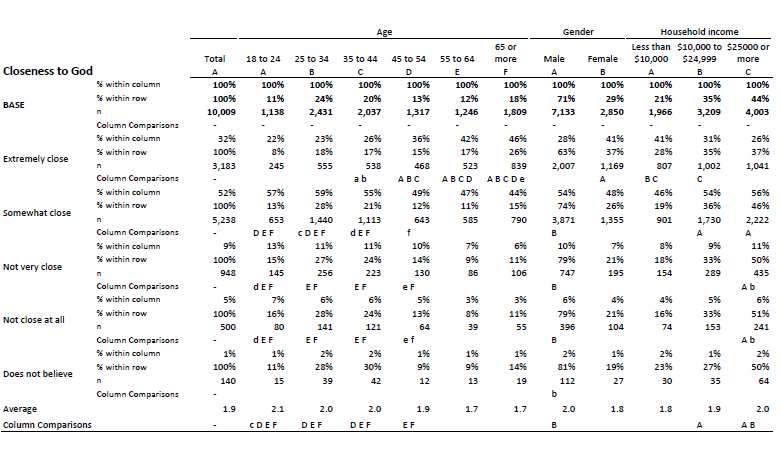
When people create old-school crosstabs, they never create just one. Instead, they create a deck. Typically, they will crosstab every variable in the study, by a number of key variables (e.g. demographics). Many studies have 1,000 or more variables, and usually 5 or so key variables, which means that it is not unusual for 5,000 or more tables to be created. Old-school crosstabs actually consist of multiple tables pushed together, so these 5,000 tables may only equate to 1,000 actual crosstabs. Nevertheless, 1,000 is a lot of crosstabs to read. To appreciate the point look at the crosstab below. What do we learn from such a table? Unless we went into the study with specific hypotheses about the variables shown in the table below, it tells us precisely nothing. Why, then, should we even read it? Even glancing at it and turning a page is a waste of time.
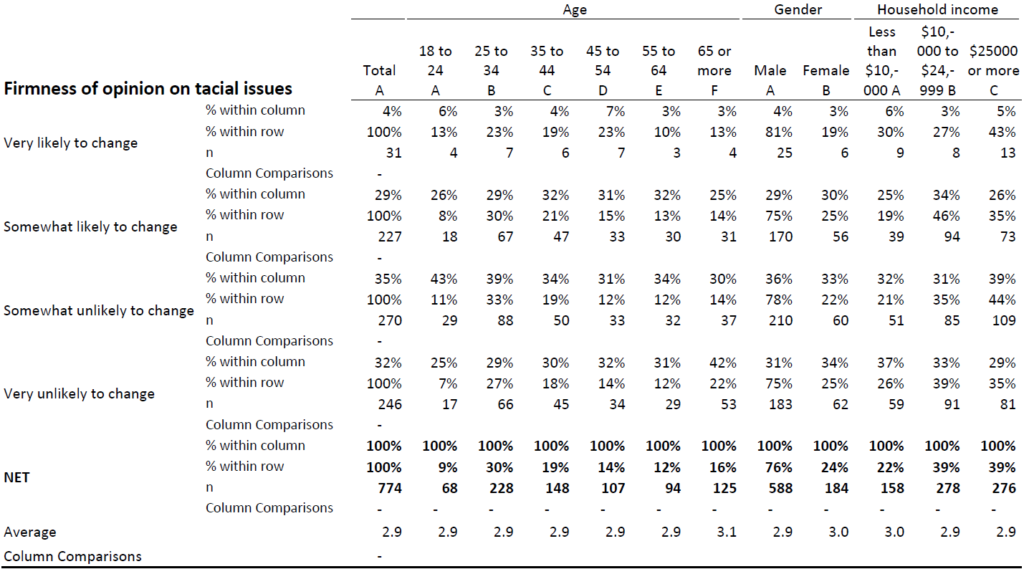
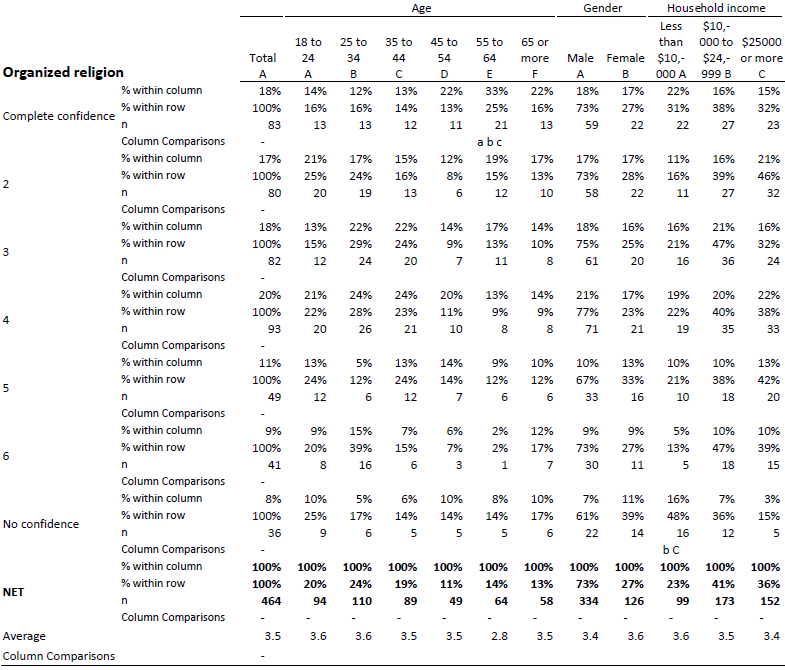
However, it is tables like the one below, which I suspect are most problematic. How easy would it be to skim this table and fail to see that people with incomes of less than $10,000 are more likely to have no confidence in organized religion? You wouldn’t make that mistake? Imagine you are skim reading 1,000 such tables late at night with a debrief the next morning.
If you instead use automatic statistical tests to scan through the tables and identify tables that contain significant results, you will never experience this problem. Instead, you can show the user a list of tables that contain significant results. For example, the viewer could be told that “Age” by “Organized Religion” and “Household income” by “Organized religion” are significant, and given hyperlinks to these tables.
DIY crosstab software
In addition to cramming together too much data and using painful-to-read statistical tests, the old-school crosstabs also show too many statistics. Look at the table above. It shows row percentages, column percentages, counts (labeled as n), averages, column names, and the column comparisons as well.
The reason that such tables are so busy is that in the olden days there was a bottleneck in the creation of tables. There were typically lots of researchers wanting tables, and only a few data processing folk servicing all of them. This meant that when we created our table specs we tended to create them with all possible analyses in mind. While most of the time we wanted only column percentages, we knew that from time-to-time it was useful to have row percentages, so we had them put on all our tables. Similarly, having counts on the table was useful if we wanted to compute percentages after merging tables. And, averages were useful “just in case” as well.
Creating tables in this way comes at a cost. First, when people ask for tables because they might need them, somebody still spends time creating them: time that will often be wasteful. And, because the tables contain information that is unnecessary, it requires more work to read them. Then, there is the risk that key results are missed and quality declines. There are two much more productive workflows. One is to give the person who is doing the interpretation DIY software, leaving them to their own devices. This is increasingly popular, and tends to be how most small companies and consulting-oriented organizations work today. Alternatively, if the company is still keen to have a clear distinction between the people that create the tables versus those that interpret them, then the table-creators can create two sets of tables:
- Tables that contain necessary and needed key results that pertain to the central research question.
- Tables that contain significant results that may be interesting to the researcher.
If the user of such tables still wants more data, they can create it themselves using the aforementioned DIY analysis tools.
Conclusion
Nothing in this post is new. (Sorry.) Using formatting to show statistical tests has been around since the late 1980’s. The first DIY crosstab tool that I know of was Quantime, launched in 1978. And, laser printers have been in wide availability since the mid-1990s.
Stopping using old-school crosstabs is just a case of breaking a habit. A good analogy is smoking. It is a hard habit to kick, but life gets better when you do. I am mindful, though, that it is more than 100 years since the father of time and motion studies, Frank Bunker Gilbreth Sr., worked out that bricklayers could double their productivity with a few simple modifications (e.g., putting the bricks on rolling platforms at waist height), and many of these practices are still not in common use. Of course, most laborers get paid by the hour, so they do not need to improve their productivity.
Software
Showing statistical tests via formatting
I used Q to create all the examples above (disclaimer: I am the CEO of Displayr, which makes Q).
Automatic screening of tables based on statistical significance
There are three main ways of screening tables based on statistical significance in Q. The most straightforward approach is to use Create > Tables > Lots of Crosstabs and then to select these tables and then run one of the options in Browse > Online Library > Delete tables and plots. Alternatives are to use Smart Tables, or to write custom QScripts.




