
Experimental Design for Conjoint Analysis: Overview and Examples

This post introduces the key concepts in designing experiments for choice-based conjoint analysis (also known as choice modeling). I use a simple example to describe the key trade-offs, and the concepts of random designs, balance, d-error, prohibitions, efficient designs, labeled designs and partial profile designs.
A simple example: brands and prices of cars
In this post I am going to use a very simple example, where we are trying to understand preferences for three brands of car – Ferrari, BMW, and General Motors – and three price points – $20K, $40K, and $100K. In the real world this would not be a sensible study, as few people really makes choices between these brands and price points. However, the example allows us to illustrate the key concepts involved in experimental designs for choice models.
The simplest way of creating an experiment is to randomly choose pairs of brands and prices. The box below shows such a random design, with 10 questions and three alternatives per question.
This questionnaire corresponds to the experimental design shown below. The first three rows show the first question, with the first row showing option 1 (alternative 1), the next three lines showing the second question, and so on.
Sometimes random designs can be a good idea – but not in this case. There are quite a lot of problems with this experimental design, and we will work through them to understand the key principles of experimental designs for choice models.
The problem of balance
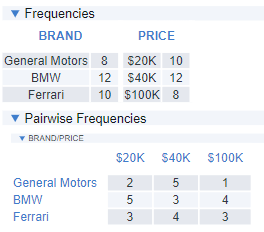
The first of the tables below shows the frequency with which each of the brands appears. As the design has been created randomly, by chance alone we end up collecting 50% more data on BMW than on General Motors. We have a similar problem when we look at the pairwise frequencies, with BMW tested at $20K five times but General Motors at $100K only once. To use the jargon, this experimental design is not balanced.
Increasing the number of versions
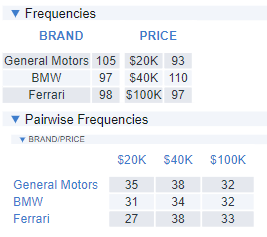
The simplest way to fix this problem is to have multiple versions of the questionnaire. A rule of thumb is to have a minimum of 10 different versions of the questionnaire (even better is to have a separate version for each respondent). When we do this, we do end up with a much higher level of balance, as shown by the tables below.
Using designs that ensure balance
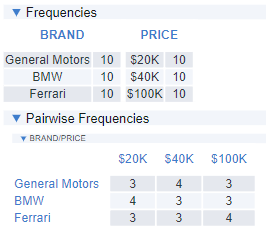
While having multiple versions improves the level of balance overall, we can further improve the design by using more sophisticated approaches to creating it. This ensures that the design is as balanced for each person as possible. For example, if we use the Balanced overlap algorithm, we end up with a design where there is a high level of balance for each respondent.
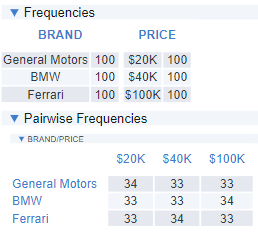
And across all 10 versions, the pairwise balance is even better.
Comparing designs with d-error
A way of evaluating an experimental design is to compute its d-error. The d-error for the random design is 0.071, and for the balanced overlap design it is 0.056. That is, the balanced overlap design has a d-error that is 23% lower. This means that if we use the balanced overlap design, we can get the same level of precision from a study with 23% fewer respondents (all else being equal).
Avoid asking too many “easy” questions
The designs so far are pretty dumb. The box below shows one of the questions created by the balanced overlap design. It asks somebody to choose between a Ferrari at $20K versus General Motors at $100K. While there is something that can be learned from such a question, for most people the choice will be pretty simple (even if they don’t want a Ferrari, they can buy it for $20K and resell it for much more). Looking at the table of pairwise frequencies above, we can see that General Motors was shown 33 times at $100K and Ferrari 33 times at $100K, so the problem is widespread. This is an inevitable consequence of striving for balance in the experimental design.
Prohibitions
One way to solve the problem of asking people dumb questions is to use prohibitions, which are rules stipulating that certain combinations may never appear (e.g., Ferrari should not appear at $20K). While this is done in real studies, it is a crude hack rather than a good idea. The basic problem with this approach is that it tends to massively reduce the efficiency of the design, and sometimes causes mistakes that make the data uninterpretable. For example, if you decide that Ferrari can only be shown at $100K, then you end up not being able to understand how price influences preferences for Ferrari. It would be fair to say that no expert has recommended the use of prohibitions for at least 20 years, so if you find yourself thinking they are a good idea, read on to learn about better approaches.
Efficient designs with priors
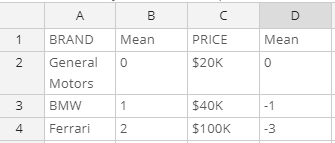
Fortunately, there is a straightforward solution to the problem of brand and price. What we need to do is work out, using our judgment, the typical preferences for each of the different brands. For example, in the table below, I’ve specified the average levels of utility for the brands and the prices. There are a couple of rules about doing this:
- Set the mean utility for the first level to 0.
- Typically, set utilities in the range of around -3 to 3. Technically, the utilities are specified in logit scale and there are situations where bigger numbers are appropriate, but using a bit of gut feel and keeping them in the range of -3 to 3 will do an OK job.
Once we have worked out the prior utilities, we can get a computer program to create an efficient design. Essentially, these algorithms start with a balanced design and then make improvements so that d-error is minimized. The frequencies from the resulting design are shown below. Note that we do see Ferrari at $20K, but only 7 times, compared to 51 times at $100K.
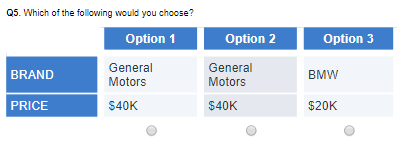
However, it is still not a good design. Look at one of the questions generated from the design. It’s got the same option twice!
(It is also possible to create even more advanced efficient designs, where in addition to specifying the prior for the mean, you also specify a prior regarding how much variance you expect between people in terms of the mean.) 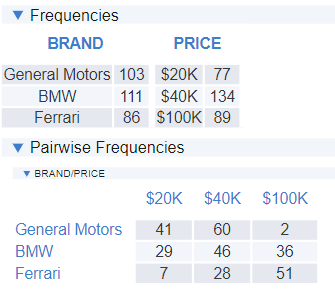
Labeled choice experiment
The choice experiment above is an unlabeled experiment, which is to say that the option names at the top – Option 1, Option 2, and Option 3 – are assumed to convey no meaning to the respondents. We can improve on our experiment by showing the brand as a label for each alternative. A labeled experiment is one where one of the attributes is used to name the alternatives and each of its levels appear at most once (designs where some alternatives appear some of the time are known as availability designs).
None of these
Both labeled and unlabeled choice experiments can have an alternative without any attributes. This is colloquially known as the “none of these” option, although in academic circles this is often referred to as the outside option. Studies can have multiple such options (e.g., “I would keep my current car”, “I would take a train”, “I would stay at home”).
Alternative specific designs
We can further improve on our car design by creating a labeled choice experiment, in which we have separate attributes for each alternative. In this example, we could have a price attribute for General Motors with levels of $15K, $20K, and $25K, for BMW of $35K, $40K, and $45K, and for Ferrari of $80K, $100K, and $120K. Such designs are known as alternative specific designs. In this example each of the attributes are price attributes, but there is no need to have the same thing be measured in each. For example, we might have an attribute relating to fuel type (Gas, Hybrid, Electricity), for GM, and an engine power attribute for only BMW and Ferrari.
Partial profile designs
The designs I have described so far work well with up to four and sometimes as many as six attributes. However, they become impractical with more attributes than this.
Returning to unlabeled choice experiments, it is quite common to have situations where there there is a desire to have more than a few attributes. For example, in a study we recently did of fast food restaurants we had 14 attributes. Consider the resulting question below. There is far too much information for most people to process.
A solution to this is to create partial profile designs, where only a subset of the attributes appear in each question, as shown in the example below (scroll to see additional questions). While this can make questionnaires much more manageable, it has a very serious effect in terms of d-error, and the partial profile design below requires 2.7 times the sample size of the impossible design above. One solution to this is to ask people more questions.
Hybrid/adapt conjoint analysis
Another approach to dealing with larger numbers of attributes is to combine together one of the approaches above with more traditional rating scales. Such approaches have various names, including adaptive choice-based conjoint and hybrid conjoint. My own experience is that these techniques do not work; the reason that conjoint is popular is because traditional ratings tend not to be very reliable. However, others disagree with this!
Sample size, number of questions, number of alternatives, and number of attribute levels
There are a number of other considerations that are relevant when creating an experimental design for a choice modeling study. In particular, there are the interrelated questions of how many people to interview, how many questions (tasks) to ask each, how many alternatives to show, and how many levels of the attributes to use. These are all discussed in the post Sample Size for Conjoint Analysis.


