
Conjoint Analysis: The Basics
Choice-based conjoint analysis is a technique for quantifying how the attributes of products and services affect their performance. It is used to help decision makers work out the optimal design of products and pricing.
Typical examples include: cost benefit analysis for planning new transportation options (e.g., new train lines), designing new cabins on airplanes (e.g., legroom, beverage, in-flight entertainment), creating new breakfast cereals, etc. (see Main Applications of Conjoint Analysis for more info).
Choice-based conjoint analysis has lots of other names, and is variously known as choice modeling, stated preference choice modeling, discrete choice experiments, experimental choice modeling, choice-based conjoint (CBC), and sometimes as just conjoint. In this post, I’ll go over the core output of choice-based conjoint analysis, its assumptions as well as the two main variants of choice modeling – revealed preference and stated preference choice modeling.
The core output of a conjoint analysis: the choice simulator
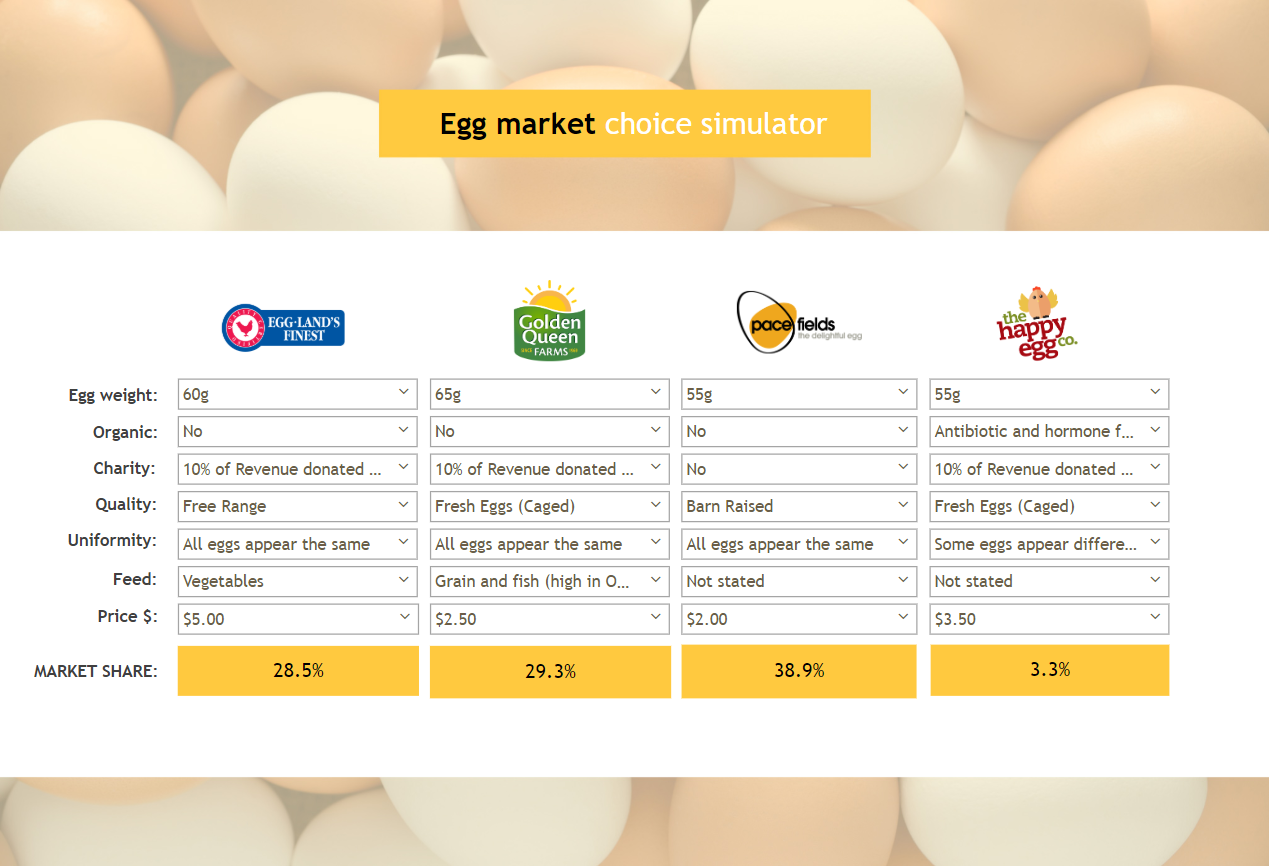
There are many possible different ways of reporting the results of conjoint analysis, but the main output is a choice simulator. A choice simulator is an interactive app that makes some kind of prediction – most commonly market share – and allows the user to see how making changes affects the predictions (e.g., what happens when the price of one brand is increased by $1?).
We created the simulator below in Displayr and you can easily play with it by clicking here or the image below.
The basic theoretical assumptions
Just about all real-world applications of choice-based conjoint analysis start from four basic assumptions:
- Products and services can be described in terms of attribute levels
- An attribute level has a utility
- The appeal of a product is the sum of the utility of its attribute levels
- People are more likely to choose products with more utility
Assumption 1: Products and services can be described in terms of attribute levels
The first column of the table below lists seven attributes of packaged eggs market. Each attribute consists of a series of attribute levels. We can see that the attribute ‘Weight’ has four levels: 55g, 60g, 65g and 70g, ‘Quality’ has three levels, etc. The first assumption of choice-based conjoint analysis is that we can think about a product as being a bundles of attribute levels.

Assumption 2: An attribute level has a utility
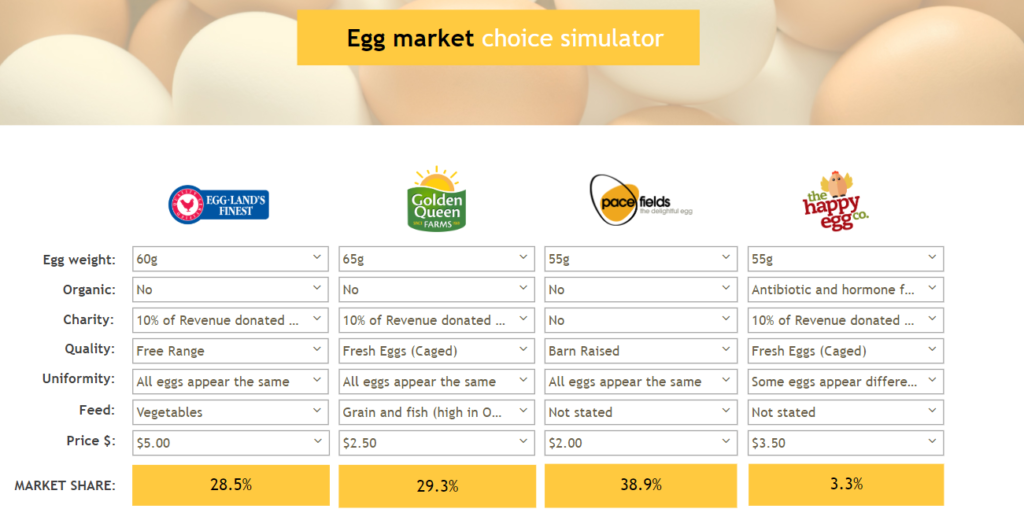
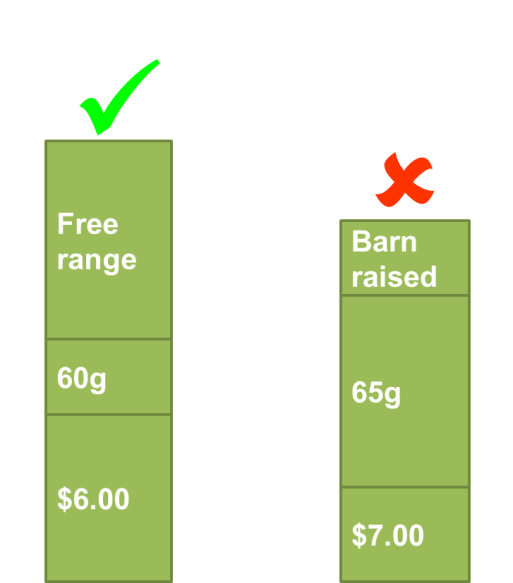
The second key assumption of choice-based conjoint analysis is that different attribute levels have different levels of appeal, where the jargon for this level of appeal is utility. For example, with the ‘Egg Quality’ attribute, consumers may have a utility for caged eggs, barn raised eggs and free range eggs – the purpose of the choice-based conjoint analysis is to estimate these utilities. Choice-based conjoint analysis studies only calculate the relative utility of different attribute levels.
For example, we never estimate the actual appeal of free range eggs; rather, we estimate the appeal of free range eggs relative to some other attribute level, such as caged eggs or barn raised eggs. For this reason, we set one of the levels as having a utility of 0, and then the utilities of the other attribute levels are estimated relative to this attribute’s level, as shown below. Most commonly, the least appealing attribute level is chosen to have a utility of 0, although there are other rules (e.g., to scale the utilities to have an average value of 0).
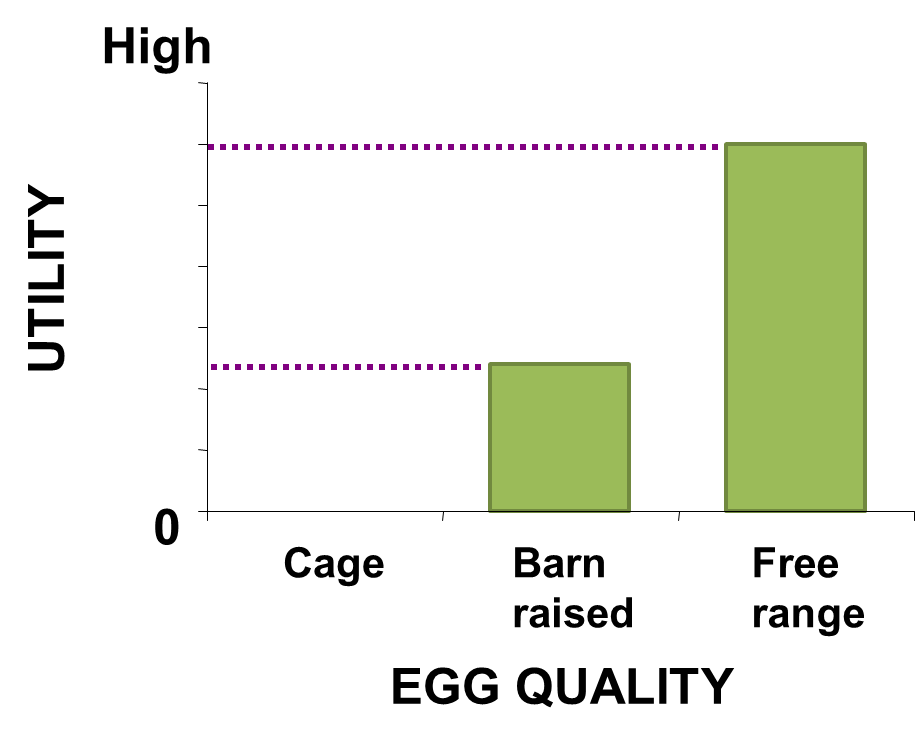
Assumption 3: The appeal of a product is the sum of the utility of its attribute levels
The third key assumption is that the utility (appeal) of a product or service can be computed by summing up the utility of its constituent parts (i.e., the attribute levels)., as shown below.
Assumption 4: People are more likely to choose products with more utility
The final key assumption of choice-based conjoint analysis is that people choose, or are most likely to choose, the product with the highest utility. This is shown graphically below.
It is easy to identify situations where some or all these assumptions are implausible. Consider perfume. Other than brand and price, what are the attributes?
Nevertheless, these four assumptions are the only practical assumptions. Meaning that the question of whether these assumptions accurately represent how people think is irrelevant as there is not another set of assumptions that allows us to make coherent predictions.
The main variants of choice-based conjoint analysis
A choice model can be created using statistical analysis of historic data, such as such as in-store purchases at supermarkets or diaries recording people’s historic choices. Such choice models are known as revealed preference choice models, as the preferences are seen as being revealed by real-world behavior.
While revealed preference models sound like a really clever thing to do, they rarely work out so well in practice. They are hamstrung by a fundamental truth: there is no historic data relating to the attribute levels of interest. For example, if Ben and Jerry’s want to work out the impact of, say, Koala ice cream, using Fish Food as a surrogate is not going to be useful.
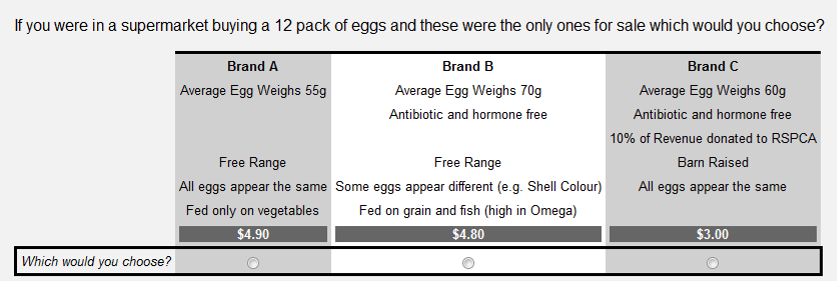
The alternative to revealed preference choice models is stated preference choice modeling. This comes in many flavors, but these days the norm is to use choice-based conjoint, also known as choice experiments, which involves presenting people with choice questions like the one below. Each person is typically shown anywhere from 1 through to 20 of these, and then, using advanced statistical techniques, it is possible to estimate each person’s utility for each attribute level.

It’s the closest thing to a crystal ball
Choice-based conjoint analysis is the closest thing we have to a crystal ball. It allows us to answer ‘what if’ questions about things that have not happened yet. Pretty cool, right? It does so in a way that explains how differences in products and attribute levels contribute to the utilities or appeal of the products. While, they may not be super accurate – just like the fortune tellers of yore – they are the best technique for answering many questions. Don’t fear though, there are things we can do to increase their accuracy.


