
The Complete Guide to Market Research
Advanced Questionnaires: New Product Development
New Product Development
Ideation
The basic idea
Once a firm has identified the general area on which it wants to concentrate its new product development efforts, the next step is to come up with ideas. Sometimes this is done by technical specialists, such as food technologists and engineers. However, in other situations it is done using ideation. When market researchers are involved this ideation tends to involve consumers, but the same basic method can be used with stakeholders and other employees of the company. Ideation is short for idea generation. Ideation itself is just an application of brainstorming.
Brainstorming
The basic logic of brainstorming is this: the best way of coming up with a good idea is to come up with lots and lots of ideas. A team that creates 50 ideas and chooses the best will, in general, end up with a much better idea than a team that that comes up with only 20 ideas. A way of coming up with lots of ideas is as follows:[1]
- Get a group of people together, but get each to initially work on their own. The widespread belief that people get ideas by bouncing off each other is not supported by evidence.
- Give people a specific target in terms of the number of ideas to come up with. For example, give them a target of 10 new ideas in 10 minutes. The trick is to make the target hard – the harder the target, the more ideas people will create. Furthermore, the specific goal is to come up with lots of ideas, not a small number of good ideas, and people should be instructed that quantity, not quality, counts.
- Then, as a group, review the ideas to identify winners.


Encouraging creativity
Ideation projects usually contain a couple of twists on traditional brainstorming. One of the twists is to give people a warm up task to encourage their creativity. The other is to give them tasks designed to guide them towards better ideas.
Example of a warm up task[2]
- Generate two lists each of four random words (e.g., by randomly opening pages of a dictionary). For example:
toast runway prophet formula chip lollipop tail pyramid
- On some basis, pair words in each of the lists
- Define the basis for the pairing. For example:
“toast” and “prophet” are both edible “tail and "formula” can be very long “profit” and “runway” suggest departure for the future
SCAMPER
SCAMPER is a checklist of activities designed to spur creative thinking, all of which start by thinking about how to modify an existing product or service:
- Substitute something
- Combine it with something else
- Adapt something to it
- Modify or Magnify it
- Put it to some other use
- Eliminate something
- Reverse or Rearrange it
Gap Identification
The most common role that market research plays in helping companies to create new products is to identify gaps in the market, where a gap is an unmet need, want or identification of a problem with existing products. This page describes three related approaches to this problem; there are numerous other approaches.
Jobs-to-be-done
Any purchase can be thought of in terms of the jobs that need to be done which motivate the purchase. When buying a car, we may have in mind the jobs of getting to work, transportation to holidays and keeping up with the Joneses. When buying yogurt, the jobs to be done may include functional jobs, such as losing weight and satisfying hunger, emotional jobs such as making us happy and social jobs such as impressing people. The jobs may need to be done regularly, such as filling our stomachs, or they may be one-off jobs. They can be driven by a specific situation, such as having had to skip a meal, or be intrinsic to the person, such as a desire for a snack at the same time every day. The following table shows jobs to be done in the yogurt category.
| Satisfy hunger | Lose weight / Maintain current weight |
| Boost blood circulation | Manage arthritis |
| Boost immunity | Manage cholesterol |
| Build / Tone muscles | Manage diabetes |
| Cool down | Relieve muscular pain |
| Ease allergies | Relieve stress |
| Fix / Maintain digestion / bowels activities | Re-energise |
| Improve brain functions (e.g. Memory, alertness) | Satisfy thirst |
| Improve vision | Strengthen bones |
| Improve quality of sleep | Strengthen nails |
| Have shiny hair | Strengthen teeth |
| Indulge | Ward off / Prevent cancer |
| Look younger |
Note how different these are to generic statements of benefits and needs; they are all precise descriptions of activities that people do, or things they may want a yogurt to provide. When trying to come up with a list of jobs, it can be useful to focus on ancillary jobs, which can be split into related and unrelated ancillary jobs. When Apple launched the iPod, it not only provided a device for playing music, it also solved the related problems of buying and cataloging music. Similarly, Nespresso solves the problem of buying, storing and grinding coffee. Non-related jobs are jobs that can be done at the same time, such as taking photos with a camera or drinking coffee while driving (which is facilitated by cup-holders).
Constraints
Once we have identified the jobs-to-be-done, there are usually two ways that we can get more detailed information about the jobs. We can focus on constraints that prevent jobs from being done well and outcomes which are desired from jobs. It is often helpful to prioritize jobs to be done in terms of how many people need to do these jobs, how important they are and how dissatisfied people are (each of which can can be measured using standard questions in a questionnaire (e.g., How important...). If a job is common, important and people are dissatisfied with the products they currently use for the job, then the job presents more of an opportunity. For example:
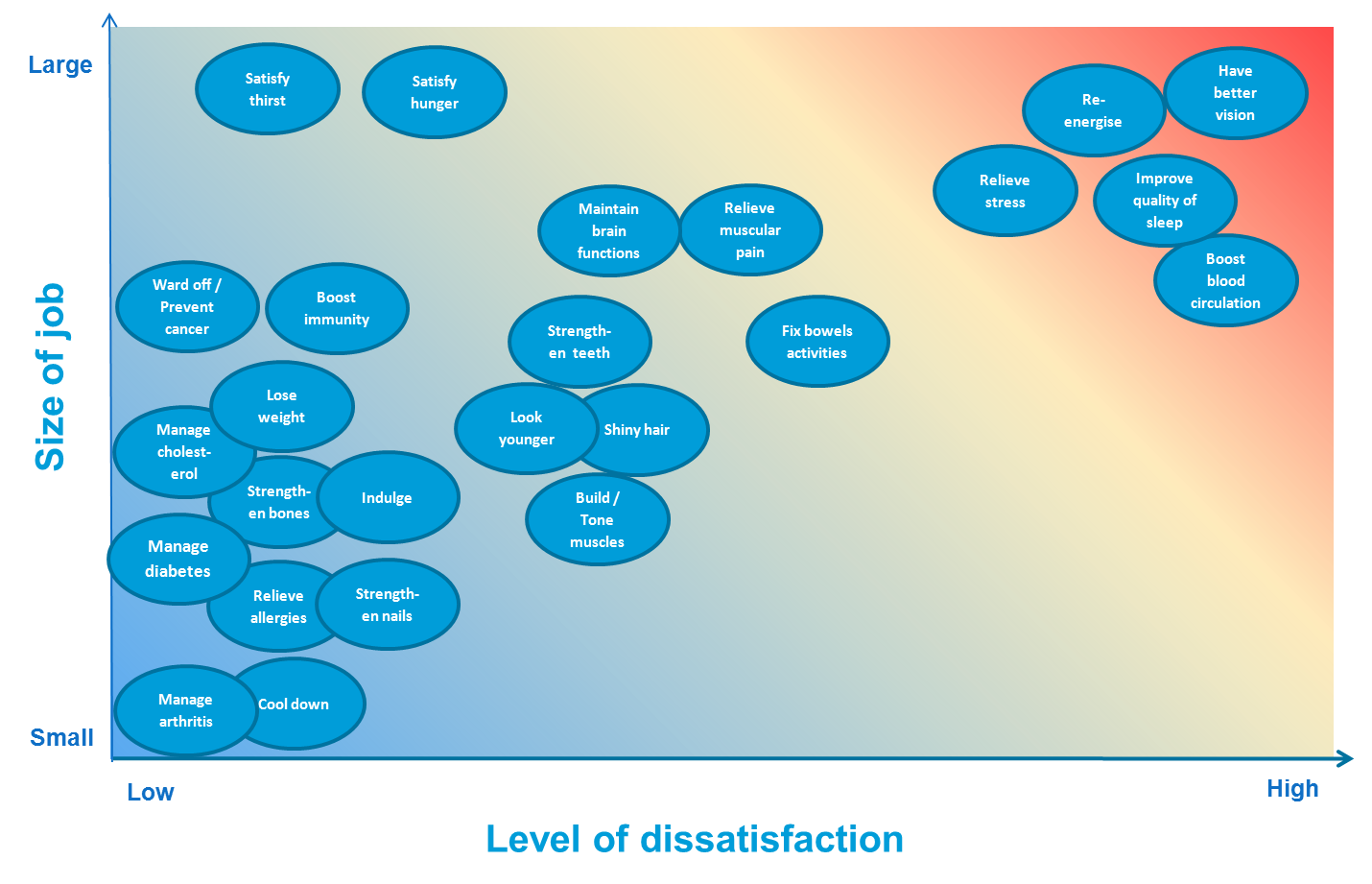
A constraint is something that prevents a job from being done or adversely impacts the outcome. The identification of constraints can be particularly helpful with new product development. When we focus on what consumers want, we are leaving it to the consumer to tell us what innovations they desire and they often do not have the insight or understanding of possibilities to be able to do this. Think about the coffee market five years ago. Research continued to show the important emotional and social role of coffee. The true aficionados wanted to be baristas in the comfort of their own homes. And what new products were targeted at this segment? Mini industrial coffee makers, designed to replicate the gourmet café experience, but with an emphasis on simplicity and ease of cleaning.
The Nespresso machine has been the standout success in this segment in recent times. Interestingly, it fails in terms of most of the key needs were identified if research into coffee before the Nespresso was launched. The user is nothing like a barista; they just drop a pod into a machine and press a button. How could such a functional product meet the market’s aspirations? It does so because it deals with all the constraints of the coffee making jobs. It is very fast. It is easy to clean. People can have much greater control over getting their perfect brew, with different varieties of coffee for every person. They can order online.
Outcomes
It can be useful to break down a job into a series of outcomes. An outcome is an assessment of how well a job has been done. For example, these outcomes relate to the ‘satisfy hunger’ job performed by yogurt:
| Decrease price / cost | Increase enjoyment |
| Decrease time taken to plan meal | Decrease guilt |
| Decrease time taken to shop | Decrease saturated fats |
| Decrease serving difficulty | Decrease calories |
| Decrease consumption difficulty | Decrease food intolerance |
| Decrease time to prepare | Increase ease of eating ‘on the go’ |
| Decrease time to clean up | Increase environmental sustainability |
| Increase time until I become hungry next |
Identifying and measuring jobs-to-be-done, constraints and outcomes
Jobs, constraints and outcomes are relatively easy to identify through any or all of qualitative research, introspection, discussions with stakeholders and reviewing previous studies. Various Ideation techniques, such as SCAMPER, can be useful.
If an outcome is both important and consumers believe that current products do badly on the outcome, this suggests that there is a gap in the market relating to this opportunity. One method for quantifying the resulting opportunities is to:
- Get consumers to rate the importance of each outcome on a scale of 1 to 10.
- Get consumers to rate their current level of satisfaction with the products they currently buy in terms of addressing these outcomes on a scale of 1 to 10.
- Prioritize the opportunities with the highest score, where the score is computed as:
Opportunity = 2 × Importance - Satisfaction
There is no great weight of scientific evidence behind this formula, but it is a useful place to start.
Concept Test
A concept test is used for measuring and understanding the appeal of a new product.
The concept board
Concept testing generally involves creating concept boards, which explain the new product to consumers, giving them enough information so that they can have a meaningful reaction when asked if they will or will not buy it. For example, this concept board was used to test the appeal for Magnum Gold prior to its launch.

Copyright Unilever Australia (used with permission)
The success of a concept test hinges on the quality of the concept’s description. It is not unknown for 20 minutes to be spent educating the respondent about a concept, but in most studies consumers get 10 to 20 seconds (which is likely sufficient for simple concepts).
If a concept board is insufficient to accurately get consumers to evaluate a concept then consumers may also be given an opportunity to trial the product. Most commonly, products will be shipped to consumers’ houses (this is called -in-home placement), or consumers will go to a central location where the concept testing may also involve some sensory research (research designed to get specific feedback on how to improve the sensory aspects of the food, such as smell, taste and viscosity). When presenting radical new technologies, the process of respondent education is called information acceleration.
The impact of respondent education can be great. One study found that after describing a concept, the proportion of respondents who said they would ‘definitely’ or ‘probably’ buy was 59% at $1.59 and 59% at $2.29 (i.e., the price had no effect). However, when the same study was conducted with an in-home use component (i.e., leaving the product with the consumers for a few weeks), price had a large effect, with the stated intention to buy being 64% at the lower price and 48% at the higher price.
When presenting complex concepts to respondents it is advisable to test for comprehension in some way, such as in Q1 of the questionnaire below.
In addition to respondent education, questions should be incentive compatible, and this is harder to achieve. Our concern is not simply one of respondents trying to mislead. There is also the issue of whether respondents will put as much effort in to answering the question as they would in a real-world purchase situation (as if their efforts are different, then their answer in the questionnaire will be unlikely to reflect what they do in reality). Most concept tests use the same structure, although questions are modified and added as required:
Concept testing questionnaire
SHOW CONCEPT BOARD
Please look at the description of the product. Please take as much time as you need to look at it. We will then ask you some questions about the product.
Q1. Is there anything in this description that you do not understand or would need more information about in order to decide whether or not to buy this product? If so, what? OPEN-ENDED
‘Q2. What, if anything, do you think you would particularly like about this product? OPEN-ENDED
Q3. What, if anything, do you think you would particularly dislike about this product? OPEN-ENDED
Q4. Which phrase from those below best describes how likely you would be to buy the product for yourself?
I would definitely buy it I would probably buy it I am not sure whether I would buy it or not I would probably not buy it I would definitely not buy it
Q5. On average, how often do you think it would be eaten?
Every day Two or three times a week Once a week Once every two/three weeks Once a month Once every two/three months Once every four/six months Less often than every six months Never
Q6. Compared with similar products how different do you think this product is?
Very different Different A little different Not very different Not at all different
Q7. How well do you think the idea for this particular snack fits what INSERT BRAND NAME means to you?
1 Does not fit at all
2
3
4
5
6
7
8
9
10 Fits extremely well
Q8. Do you have any further comments about this product? If so, what? OPEN-ENDED
Qualitative concept testing
Where the concepts are being tested using qualitative research, a similar structure is usually followed, although commonly with a general exploration of needs and wants at the beginning of the study (this can also occur with quantitative studies). Where the purpose of the concept test is to refine concepts, rather than work out which are most appealing, qual is usually more appropriate due to the potential for more depth from the diagnostics.
Analysis
Typically a concept test will involve multiple separate concepts, which are evaluated based on a combination of relative performance against each of the other concepts and internal benchmarks. Usually the key question that is used to evaluate whether the concept is a winner is Q4, which is referred to as the purchase intent question. The Magnum concept shown above was one of 26 concepts tested. The resulting concept scores were:
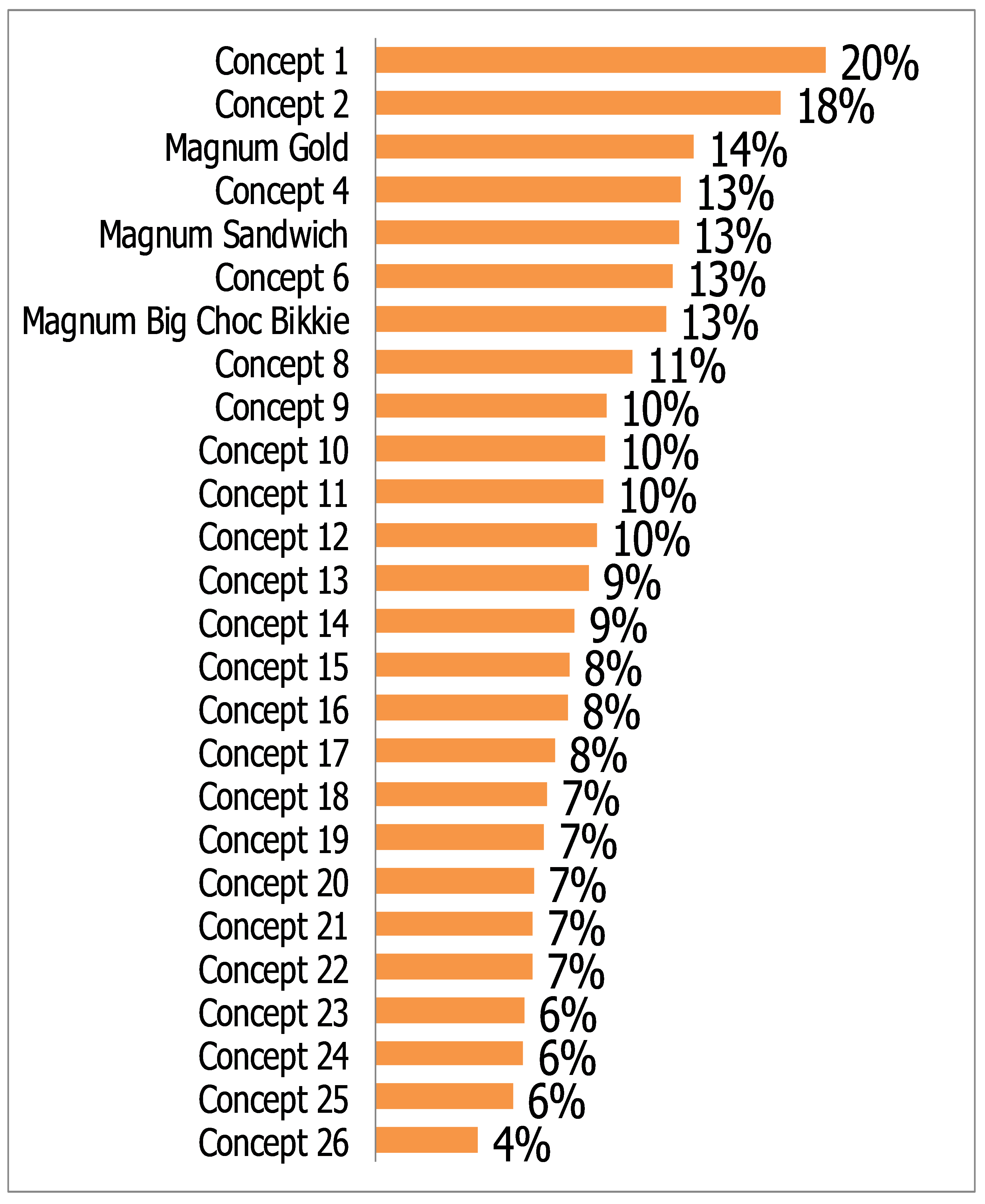
Large companies typically keep records of previous concept tests and develop benchmarks for new products. Common benchmarks include getting a top two box score of 60%, or a top box score, which is also referred to as a DWB (“Definitely Would Buy”) of 25%. Such benchmarks are rarely valid.[3] This is because people are not able to accurately state their future behavior (how can they know how much they will like an ice cream before they have eaten it) and because many other factors determine the success of a new product, such as distribution, word-of-mouth, and so on. For example, Magnum Gold’s top box score (the proportion of people to say they would ‘definitely’ buy) was 14% and its top 2 box score was 38%, which are below most commonly-used thresholds. Despite this, it went on to become the top selling ice cream in Australia. Many other products have passed these thresholds and failed.
Although it is not unusual for companies to take the approach of launching product(s) that ‘win’ the concept testing, this can be dangerous, as consumers have a tendency to give higher ratings to concepts that are similar to successful products already in the market. Consequently, the products with the highest purchase intent often face the stiffest competition if launched. One solution to this is to prioritise concepts based on a combination of purchase intention and uniqueness (e.g., as measured in Q6).
Choice Task
The purchase intention questions in a traditional Concept Test likely measure desire rather than true intention. Desire is infinite and resources are finite and we should expect that purchase intention questions will over-state demand. A solution to this problem is to ask consumers to choose from multiple products. Such choice tasks have the important advantage of most closely replicating the real world tasks that shoppers perform. For example:
If you saw the following products at these prices when you were next shopping for baby food, which of these would you buy?

Most commonly, consumers will be presented with a single screen (or piece of paper) containing descriptions of the new product and competitor products in the market segment and their prices. Consumers are asked to select only one of the brands. As they have had to make a choice between all of the available alternatives, the data implicitly takes into account the finite nature of consumers’ resources, and we expect (and often observe) a high correspondence between the proportion of respondents who select a product and the true proportion who buy it in the real world.
Of course, there is something a bit unnatural about such choice tasks, containing one new product and existing products. The poorer the correspondence between the real-world and a question being used to predict real-world behavior, the less accurate we should expect the question to be. This is referred to as ecological validity. A solution of sorts to this is to Choice Modeling, as with a choice model all of the alternatives are artificial and thus the problem of one being new is not a source of bias.
Where consumers are likely to change their purchasing in different situations (e.g., meal occasions), or due to variety seeking, these can be addressed by occasion-cuing the questions (e.g., “thinking about your last trip”, or, “thinking about your last time you went to the football”) or by using Constant-Sum questions (e.g., “thinking of your next 10 purchases, how many of each of these products would you buy?”).
Many choices tasks include an “I would not buy any of these” option. Such descriptions should only ever be included when it is a realistic outcome. As an example, if modelling airline choice, it is clearly realistic to permit a consumer to say they would choose not to fly given the available alternatives. By contrast, if modelling choice of beverage on a hot day, the inclusion of the “none” option is problematic, as in reality the consumer is likely to be forced to choose between the brands in the choice task and may select “none” as a way of signalling that they do not like these brands (even though if presented with only these brands they probably would have actually chosen one of them).
Experiments
Discrete Choice Experiments
There is a relatively simple approach to dealing with the problem of pricing the iPad which was discussed in Basic Questionnaires. The solution is to conduct an experiment, showing different people the iPad at different prices and asking them if they will or will not buy the product. For example, some people could be shown a price of $500, some $750, some $1,000 and so on. As the respondent cannot know that the experiment is designed to understand the effect of price, they have no way of providing misleading answers in order to gain a benefit. Thus, the question becomes incentive compatible.
Common types of experiments used in market research
- Completely Randomized Designs. Each respondent is shown one and only one thing (e.g., the example above).
- Max-Diff
- Conjoint Analysis
- Discrete Choice Experiments
Choice Modeling
A common problem when developing a new product is that you have a general view on what the new product should be but need to refine some of the details, such as the price point, the size or the specific combination of features to offer. Or, you may have an existing product or service and wish to work out how best to improve it. One solution to test multiple versions of a product is to conduct multiple concept tests or choice tasks. The alternative is to use choice modeling, which is essentially the same as choice tasks, except that each respondent completes multiple choice tasks and the descriptions of the alternatives change from task to task.
The basic premise of choice modelling is that rather than researching preferences for concepts, we should instead research preferences for product attributes.
The theoretical assumptions of choice modeling
1. Each product product can be described by its attributes
The first key assumption of choice modeling is that products can be described by their attributes. The table below shows attributes in the packaged eggs market. It describes packaged eggs in terms of seven attributes. Each attribute consists of a series of attribute levels. We can see that the attribute Weight has four levels: 55g, 60g, 65g and 70g.
| Attribute | Level 1 | Level 2 | Level 3 | Level 4 |
|---|---|---|---|---|
| Weight | Average Egg Weighs 55g | Average Egg Weights 60g | Average Egg Weights 65g | Average Egg Weights 70g |
| Organic | BLANK [nothing shown] | Antibiotic and hormone free | ||
| Charity | BLANK [nothing shown] | 10% of Revenue donated to RSPCA | ||
| Quality | Fresh Eggs (Caged) | Barn Raised | Free Range | |
| Uniformity | All eggs appear the same | Some eggs appear different (e.g., shell colour) | ||
| Feed | BLANK [nothing shown] | Fed on grain and fish (high in Omega) | Fed on vegetables | |
| Price | Range of price points from $3.35 to $6.50 |
2. Attribute levels differ in their appeal
The second key assumption of choice modeling is that different attribute levels have different levels of appeal. Choice modelling studies tend to use the word utility instead of appeal, but they mean the same thing. For example, with the Egg Quality attribute, consumers may have a utility for caged eggs, barn raised eggs and free range eggs, and a purpose of the choice modelling is to estimate these utilities. Choice modeling studies only calculate the relative utility of different attribute levels. For example, we never estimate the actual appeal of free range eggs; rather, we estimate the appeal of free range eggs relative to some other attribute level, such as caged eggs or barn raised eggs. For this reason, we set one of the levels as having a utility of 0, and then the utilities of the other attribute levels are estimated relative to this attribute’s level. Most commonly, the least appealing attribute level is chosen to have a utility of 0.
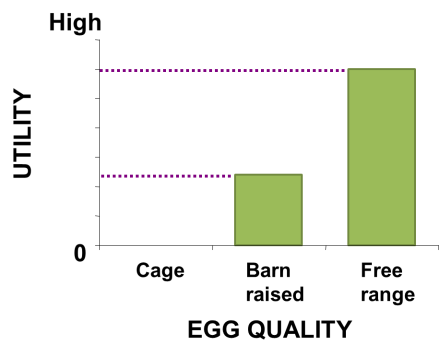
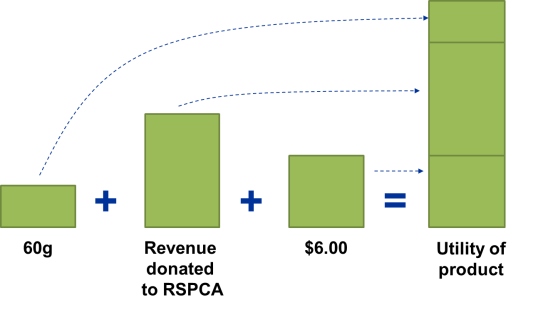
3. The appeal of a product is the sum of the appeal of the attribute levels
The third key assumption is that the appeal of a product is the sum of the utility of its product attribute levels. This is an example of the use of a decomposition.
4. People are most likely to choose the alternative with the highest appeal
The final key assumption of choice modeling is that people choose, or are most likely to choose, the product with the highest utility. This assumption can be weakened to deal with differences in distribution.

Choice modeling methods
A large number of techniques have been developed for choice modeling.
Build-Your-Own

Conjoint Analysis
Conjoint analysis is a Choice Modeling technique which involves presenting people with a series of hypothetical products, called profiles, and asks the people to rank or rate the products in order of appeal. The basic idea is that by looking at which alternatives get a higher rating (or ranking), we can understand what is important to them. For example, if somebody always rates the alternative with the lowest price the highest we can conclude that price is most important to them.
The table below contains descriptions of sixteen different soft drinks. Please rank them according to how likely you would be to buy them, writing a “1” next to your most preferred product, a “2” next to your second most preferred product, and so on until you have given ranks of “1” to “16” to the products.
| Product | Price | Brand | Size | Material | Flavour | Competition | Rank |
|---|---|---|---|---|---|---|---|
| 1 | $2 | Virgin | 300 ml | Glass | Cola | >No | ______ |
| 2 | $2 | Virgin | 300 ml | >Glass | Diet Cola | Yes | ______ |
| 3 | $2 | Virgin | >300 ml | Plastic | Cola | Yes | ______ |
| 4 | $2 | Virgin | 300 ml | Plastic | >Diet Cola | No | ______ |
| 5 | $2 | Coke | 400 ml | Glass | Cola | No | ______ |
| 6 | $2 | Coke | 400 ml | Glass | Diet Cola | Yes | ______ |
| >7 | $2 | Coke | “>400 ml | Plastic | >Cola | Yes | ______ |
| 8 | $2 | Coke | 400 ml | Plastic | Diet Cola | No | ______ |
| 9 | $3 | Virgin | 400 ml | Glass | Cola | No | ______ |
| 10 | >$3< | Virgin | 400 ml | Glass | Diet Cola | Yes | ______ |
| 11 | $3 | Virgin | 400 ml | Plastic | Cola | Yes | ______ |
| 12 | $3 | Virgin | 400 ml | Plastic | Diet Cola | No | ______ |
| 13 | $3 | Coke | 300 ml | Glass | Cola | No | ______ |
| 14 | $3 | Coke | 300 ml | Glass | Diet Cola | Yes | ______ |
| 15 | $3 | Coke | 300 ml | Plastic | Cola | Yes | ______ |
| 16 | $3 | Coke | 300 ml | Plastic | Diet Cola | No | ______ |
Discrete Choice Experiments
The most popular form of choice modeling are discrete choice experiments (also known as choice-based conjoint, CBC and sometimes just as choice modeling).
Discrete choice experiments present people with a series of hypothetical purchase situations, and require people to make a choice in each. Typically, consumers are given from six to twenty different Choice Tasks, with each question containing from two to eight alternatives. For example, the choice task below is from the egg study described earlier. In this experiment each respondent completed eight choice tasks (also known as choice sets, choice questions and scenarios), where the attribute levels of each alternative changed from question to question.
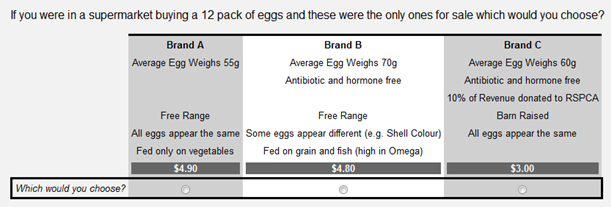
The basic idea is that by looking at which alternatives people choose, we can understand what is important to them. For example, if somebody always chooses the alternative with the lowest price we can conclude that price is most important to them.
Decompositions
The simplest and laziest approach to this problem is to do a survey. For example, you might email 1,000 people in Australia and ask how many people in each household are Japanese and have dentures. The result of this would be an estimate of the proportion of Australians that say they are Japanese and have dentures. To get to our required result we would multiply this by the number of Australians. Thus, we have used the following model:
Number Proportion Japanese = Japanese × Number dentures dentures Australians
This formula is a decomposition. We have decomposed the thing we are trying to estimate into two separate estimates – the proportion and the population size.
As research designs go this is a poor one. The proportion we are trying to estimate is likely to be a very small one (e.g., less than 0.1%). Thus, we would expect that we might need to interview well over 1,000 people before we identified a single one of them and perhaps 50,000 or 100,000 people before we obtained a sufficiently precise estimate, for a cost of millions dollars. People researching bizarre topics are usually short of funds, so we can feel confident that this research design is inappropriate. Furthermore, we probably would not get a very precise answer anyway, as if we do this study in English, Japanese speakers are relatively less likely to participate. So, how can we resolve this? There are lots of other possible decompositions. For example:
Number Number Japanese = people with × Proporton Dentures dentures Japanese
This decomposition requires two completely different inputs: the number of people with dentures and the proportion of people that are Japanese. Both of these numbers may be available from publicly available sources (e.g., trade associations, government statistics), so we might be able to do this very cheaply. Of course, the result may also be quite inaccurate, because this decomposition implicitly assumes that people of Japanese origin are neither more nor less likely to have dentures than the rest of the population.
So, we can use different decompositions to solve the same problem. The trick is to trade-off which will be cheapest with which will be most precise.
Now let us solve a more traditional problem. Consider the problem of trying to predict sales of a new brand of laundry detergent. A standard decomposition for this is:
Sales = Market Share × Market Size
There are lots and lots of ways to estimate market share. One of them is to present people with a screen showing a picture of a supermarket shelf, including the new brand, and ask people to choose one; the proportion of people that choose the new brand is then an estimate of the market share. The market size can usually be obtained from historic sales data.
An alternative decomposition of sales of a new product is:
Intention Sales = to × Purchase × Population purchase frequency size
Intention to purchase is estimated by showing somebody a picture of the proposed new product, and asking them if they will buy it or not (Concept Testing). Purchase frequency can be estimated by asking people how many times they will buy it (although looking at historical purchase rates of similar products will often be more valuable). The population size can be obtained from government statistical agencies.
When designing research we need to find the most cost-effective way of producing sufficiently precise estimates. Consider the decomposition of:
Sales = Market Share × Market Size
Let us say we are trying to forecast laundry detergent and we are trying to produce a forecast for next year. To produce our sales estimate we need to estimate market share and market size. It is inevitable that the market size will be broadly similar to the sales from the previous year, with a little growth. So, if the market size last year was $13 billion, the market size next year will probably be between $13 billion and $14 billion.
Now think about the market share estimate. If the new product is a ‘dog’, it will get 0% market share. If it is wonderful, perhaps it can get 20% of the market. So, if we multiply the lower bound estimates of market size and market share we compute a lower bound estimate sales of 0% of $13 billion = $0 and an upper bound of 20% of $14 billion = $2.8 billion. Our range of estimates for market size make comparatively little difference to our forecast. If we assume that the market size is $13 billion, this drops the upper bound from $2.8 billion to $2.6 billion. By contrast, changing the estimated market share from 20% to 0% drops the upper bound all the way down to $0. Thus, the estimate of sales is most sensitive to the estimated market share analysis and, it follows from this sensitivity analysis, that our focus in producing an estimate of sales should be on estimating the market share if we are decomposing sales into market share and market size. This process, of working out which bit of the research design will most impact upon the precision of an estimate, is known as sensitivity analysis.
Pre-launch Forecasting
As discussed earlier, there are two main decompositions used in prelaunch forecasting:
Sales = Market Share × Market Size
and
Intention Sales = to × Purchase × Population purchase frequency size
The first of these decompositions can be combined with choice modeling, as choice modeling is particularly popular in that the preference share estimate that is provided can be interpreted as an estimate of market share. Thus, as most companies have a good idea of the market size, it becomes easy to use this decomposition to predict sales.
The second of the decompositions seems sensible on face value. However, it tends to produce forecasts of sales that are much too high. This is because people are unable to gauge either their likelihood to purchase or their purchase frequency. If you think about it for a while, you will realize that the questions themselves are nearly impossible to answer. How can you rate your purchase intent, for example, if you do not know what other products will be available?
Some research companies have methods for calibrating the purchase intention and purchase frequency data with the goal of making the decomposition more accurate. These are the rules of six companies:[4]
- Company A assumed that 100% of those who say they “Definitely will buy” actually will buy (and that nobody else will buy).
- Company B assumed that 28% of those who say they “Definitely will buy” actually will buy.
- Company C assumed that 80% of those who say they “Definitely will buy” actually will buy and that 20% of those who say “probably” will buy.
- Company D assumed that 96% of those who say they “Definitely will buy” actually will buy and that 36% of those who say “probably” will buy.
- Company E assumed that the buying proportions for each of the five categories are 70%, 54%, 35%, 24% and 20%.
- Company F assumed that the buying proportions for each of the five categories are 75%, 25%, 10%, 5% and 2%.
A key point to appreciate about these different rules of thumb is the wide discrepancy in their predictions. This highlights the poor validity of purchase intention questions. Furthermore, all of the methods down-weight the purchase intentions, which highlights that purchase intentions are systematically over-stated.
Another problem with the calibration of purchase intent is that the extent of calibration required will likely relate to the number of competitors and the uniqueness of the product, suggesting that any simple approach to calibration is unlikely to be successful.
Despite the inaccuracy of questions asking purchase intentions, concept tests are very popular. In part this is because the diagnostics they provide (e.g., likes and dislikes) can be highly informative and in part it is because they are simple. Furthermore, they can be used to produce forecasts that are more valid than those of the decomposition. The trick is to study the results of previous concept tests. If, for example, you find that a top box score of 20% results in sales of $10,000,000 on average while 30% results in sales of $15,000,000 then you can estimate that a score of 25% will lead to sales of $12,500,000.
Researchers can often use substantially more complex decompositions than these for producing pre-launch forecasts. For example, some take into account factors like distribution, advertising expenditure, shelf placement and word-of-mouth.
Once a pre-launch forecast has been computed it should then be substituted into an economic analysis which takes into account the extent of cannibalization and the likely profit margin of the product.
References
[1] Rossiter, John R. and Gary L. Lilien (1994), “New ‘Brainstorming’ Principles,” Australian Journal of Management, 19 (June), 61-72.
[2] Bono, Edward de (2008), Creativity Workout: 62 Exercises to Unlock Your Most Creative Ideas. Berkeley: Ulysses Press, page 30-31.
[3] For a case study see: Bass, Frank M, Kent Gordon, Teresa L Ferguson, and Mary Lou Githens (2001), “DIRECTV: Forecasting diffusion of a new technology prior to product launch,” Interfaces, 31 (3), S82-S93.
[4] Jamieson, Linda F. and Frank M. Bass (1989), “Adjusting Stated Intention Measures to Predict Trial Purchase of New Products: A Comparison of Models and Methods,” Journal of Marketing Research, 26 (August), 336-45.